
stable diffusion介绍
Stable Diffusion是2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述产生详细图像,尽管它也可以应用于其他任务,如内补绘制、外补绘制,以及在提示词指导下产生图生图的翻译。
安装
Windows安装
要求:
(1)需要拥有NVIDIA显卡,GT1060起,显存4G以上
(2)操作系统需要win10或者win11的系统
(3)电脑内存16G或者以上
(4)最好魔法上网
本地部署Stable diffusion WebUI项目
1、安装miniconda
用来管理本地python版本
下载地址:https://docs.conda.io/en/latest/miniconda.html#installing
下载对应的系统版本,一路next
搜索miniconda,打开命令窗口,输入conda -V 验证是否安装完成 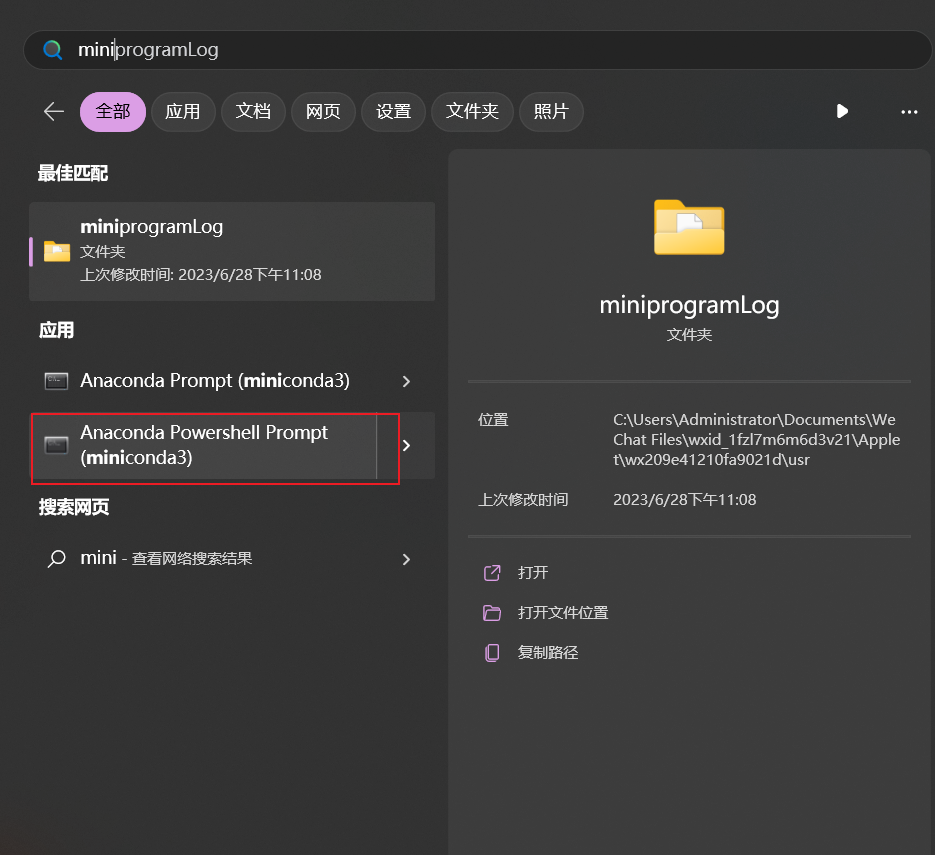

如果没有可以全局代理的魔法上网环境,需要配置国内镜像加速下载项目依赖
执行下边命令生成.condarc文件
conda config --set show_channel_urls yes将下边的内容复制到 .condarc 文件,该文件的目录一般在 C:/Users/{userhome}/.condarc
channels:
- defaults
show_channel_urls: true
default_channels:
- http://mirrors.aliyun.com/anaconda/pkgs/main
- http://mirrors.aliyun.com/anaconda/pkgs/r
- http://mirrors.aliyun.com/anaconda/pkgs/msys2
custom_channels:
conda-forge: http://mirrors.aliyun.com/anaconda/cloud
msys2: http://mirrors.aliyun.com/anaconda/cloud
bioconda: http://mirrors.aliyun.com/anaconda/cloud
menpo: http://mirrors.aliyun.com/anaconda/cloud
pytorch: http://mirrors.aliyun.com/anaconda/cloud
simpleitk: http://mirrors.aliyun.com/anaconda/cloud运行 conda clean -i 更新索引缓存
一些简单的conda命令
# 列出已经安装的环境
conda info --env
# 创建一个python3.10.6的环境
conda create --name py3.10.6 python=3.10.6
# 激活环境
conda activate py3.10.6
# 删除环境
conda remove -n py3.10.6 --all2、创建python开发环境
运行下边命令,创建环境
conda create --name stable-diffusion-webui python=3.10.6一路Y,然后最后会显示 done 就创建完成了,创建的目录为 C:\ProgramData\Miniconda3\envs\stable-diffusion-webui
3、激活环境
输入以下命令,激活环境
conda activate stable-diffusion-webui 升级pip,并设置pip的默认库包下载地址为阿里云镜像
升级pip,并设置pip的默认库包下载地址为阿里云镜像
# 升级pip
python -m pip install --upgrade pip
# 设置pip阿里云镜像
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple4、安装cuda
要想使用NVIDIA显卡来跑算法,需要安装cuda
(1)打开英伟达cuda官网,https://developer.nvidia.com/cuda-toolkit-archive
(2)查看自己显卡适配的cuda版本
miniconda 控制台输入 nvidia-smi.exe ,查看 CUDA Version ,我的是11.0,所以我就下载 11.0.x 版本的cuda 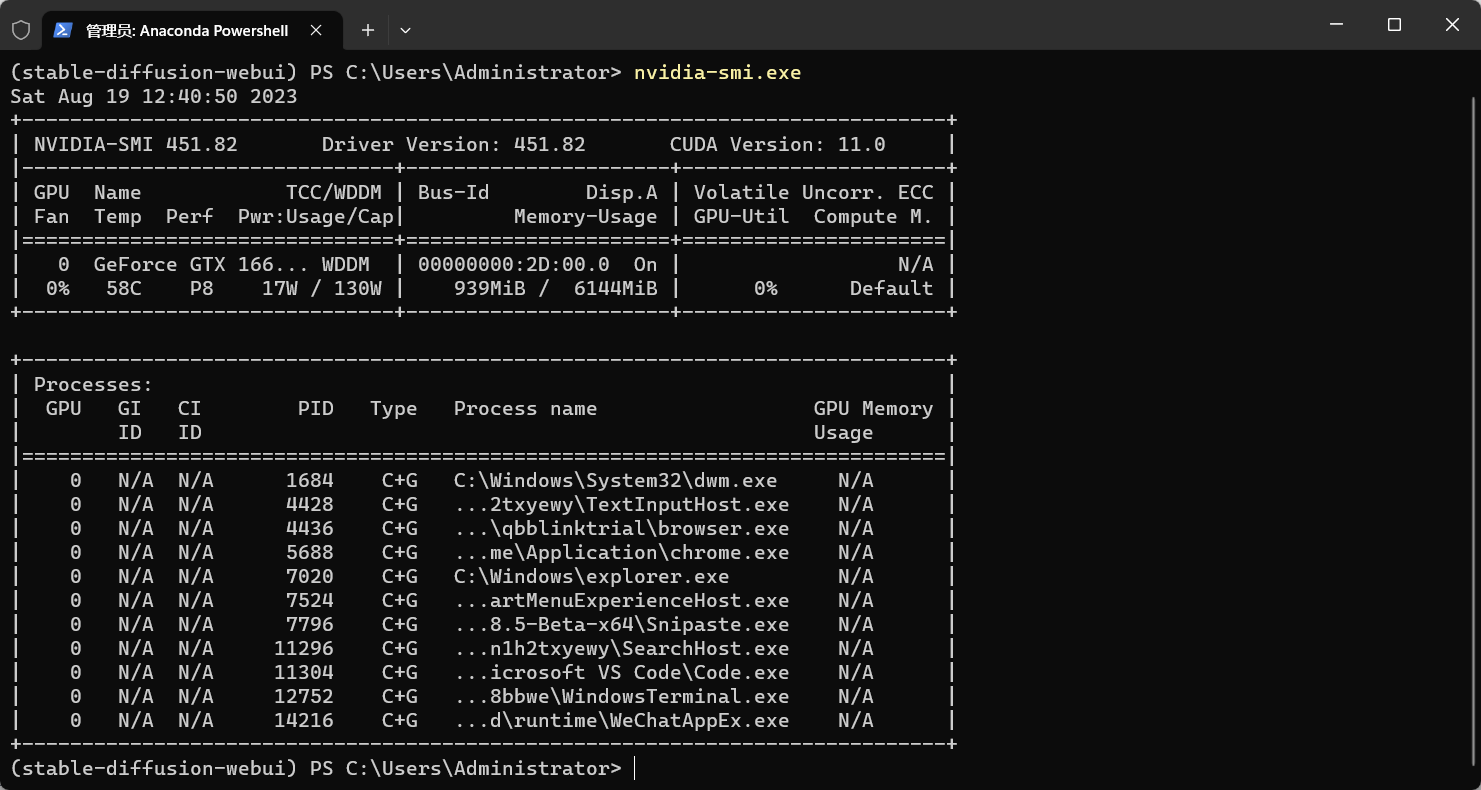
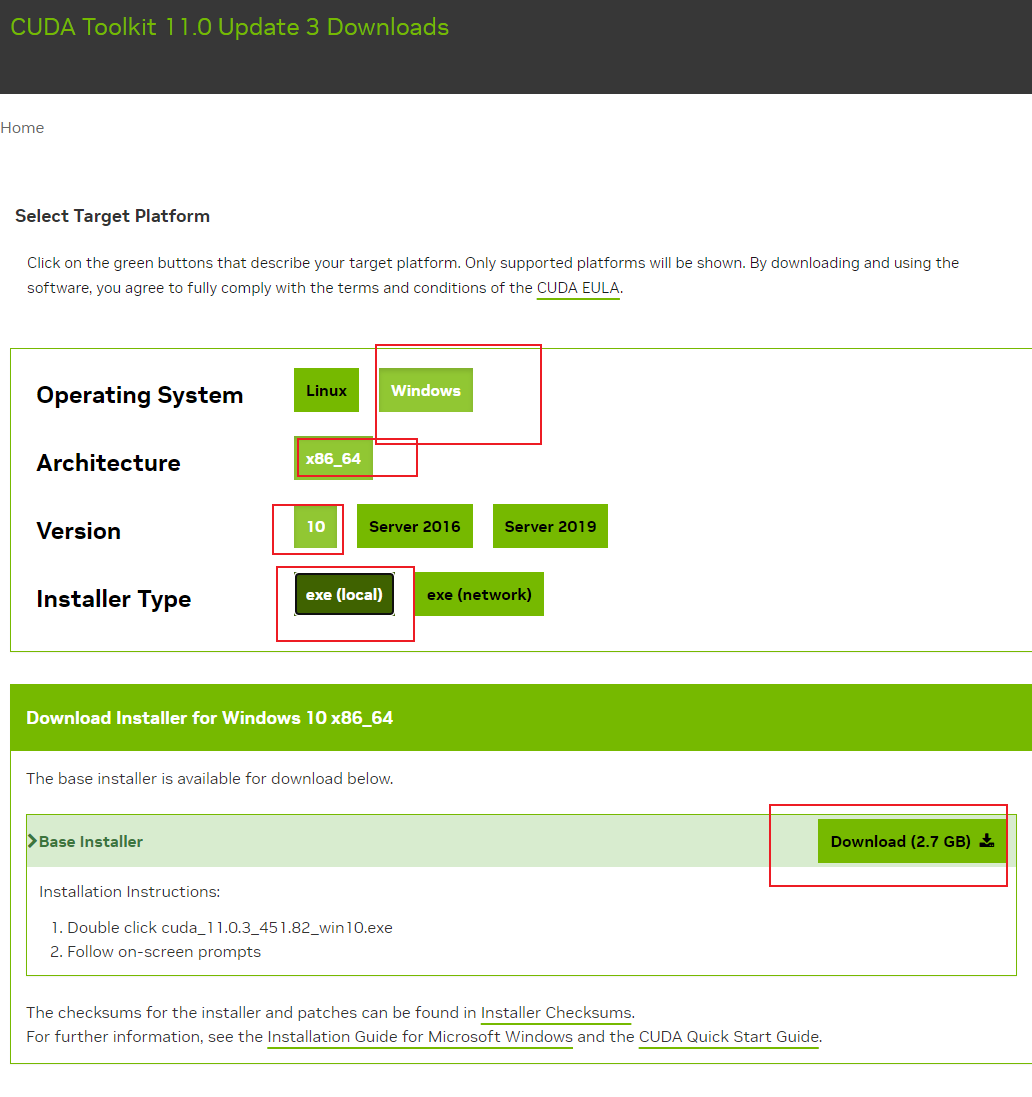
下载完之后,安装可以选择D盘等空间较大的盘,我这里选择的D盘,一路next安装完成,这样python cuda的环境就配置好了
5、安装stable diffusion web ui
下载stable-diffusion源码
选择合适的目录,使用命令,目前我安装的是 v1.5.1 版本
git clone -b v1.5.1 https://github.com/AUTOMATIC1111/stable-diffusion-webui.git6、启动stable-diffusion-web-uii项目
在miniconda命令窗口下,激活stable-diffusion-webui空间,如果已经在stable-diffusion-webui空间下了,就可以直接进入到代码目录下执行 webui-user.bat 文件
如果你的项目在启动过程中,下载依赖的时候超时无法启动,找到对应的报错,进入 launch.py 文件,查找对应报错的行一般为run_pip 指令,指定豆瓣源 -i https://pypi.douban.com/simple/,例如:
if not is_installed("gfpgan"):
#run_pip(f"install {gfpgan_package}", "gfpgan")
run_pip(f"install -i https://pypi.douban.com/simple/ {gfpgan_package}", "gfpgan")
if not is_installed("clip"):
run_pip(f"install -i https://pypi.douban.com/simple/ {clip_package}", "clip")
if not is_installed("open_clip"):
run_pip(f"install -i https://pypi.douban.com/simple/ {openclip_package}", "open_clip")如果你的项目启动报错xformers相关,启动时指定参数如下,进入到代码目录,找到webui-user.bat文件,
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--xformers
call webui.bat至此,stable diffusion webui安装完成,打开命令提示框里的Running on local URL 对应的地址 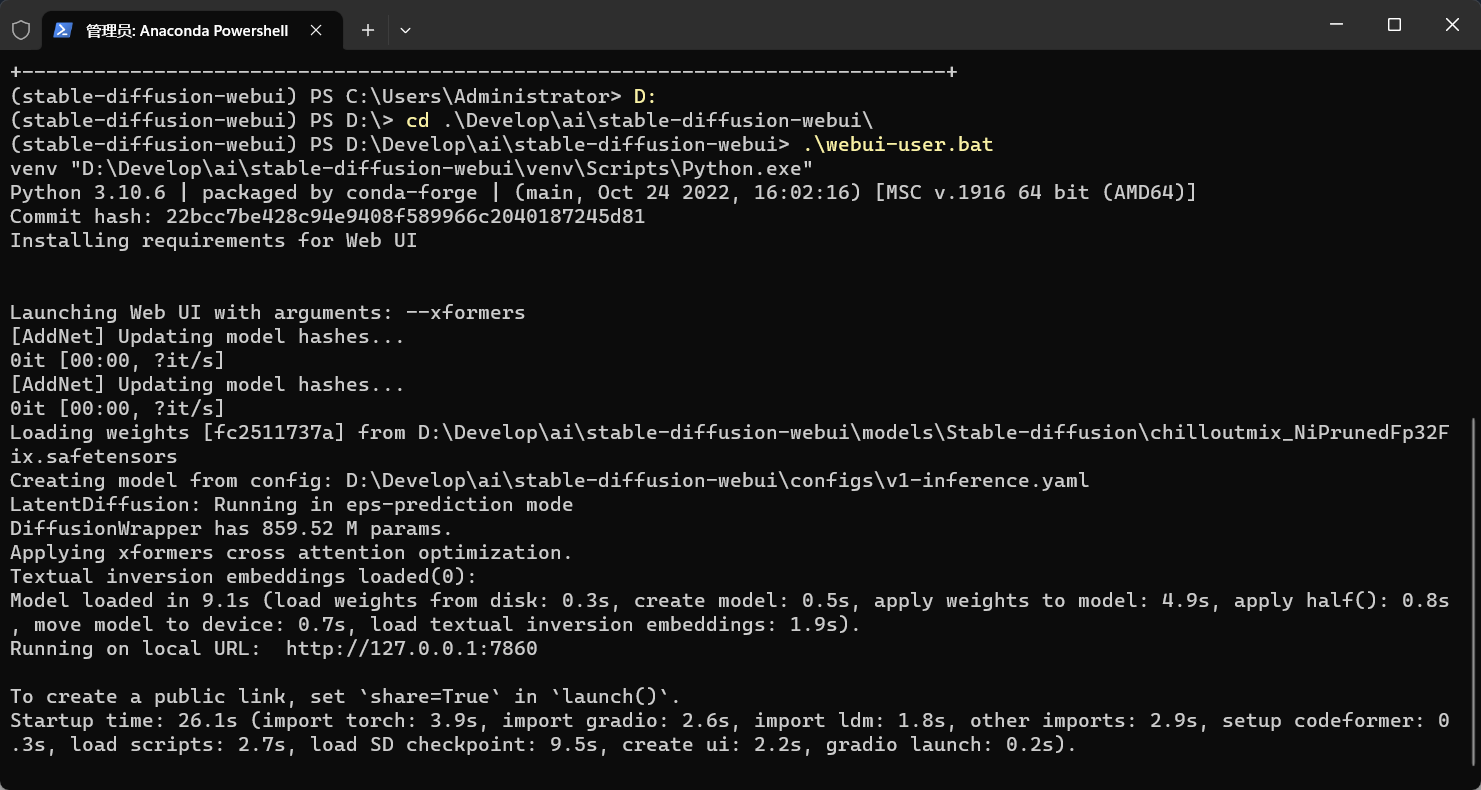
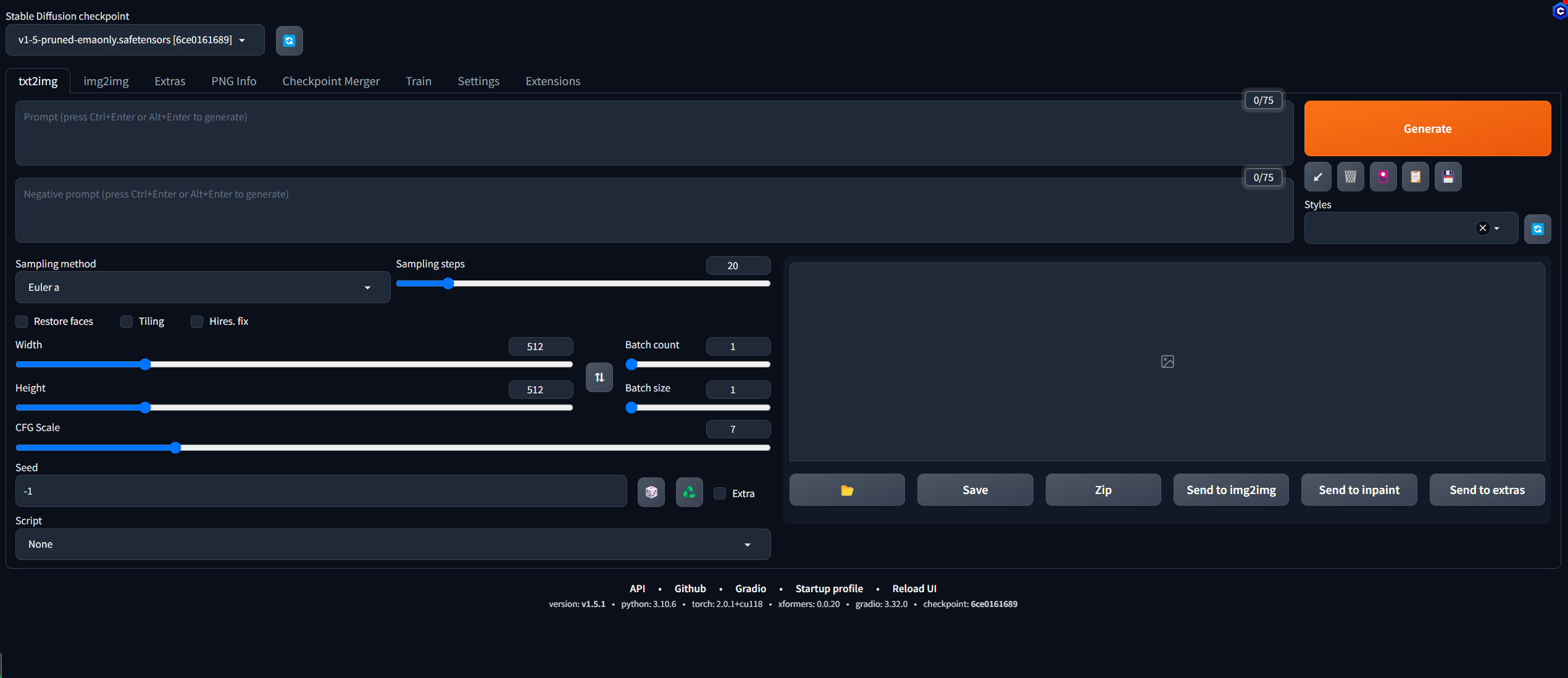
模型的下载安装和使用
stable diffusion的使用需要一些预置的模型,可以自己训练,成本比较高,也可以使用已经训练好并开源的模型,比如大名鼎鼎的C站(civitai),出于一些原因,C站需要魔法上网才能看 
C站的模型主要介绍两类,CheckPoint,LoRA
CheckPoint模型
模型的下载和安装
首先需要先查找到自己喜欢的风格的模型,就在C站就可以了 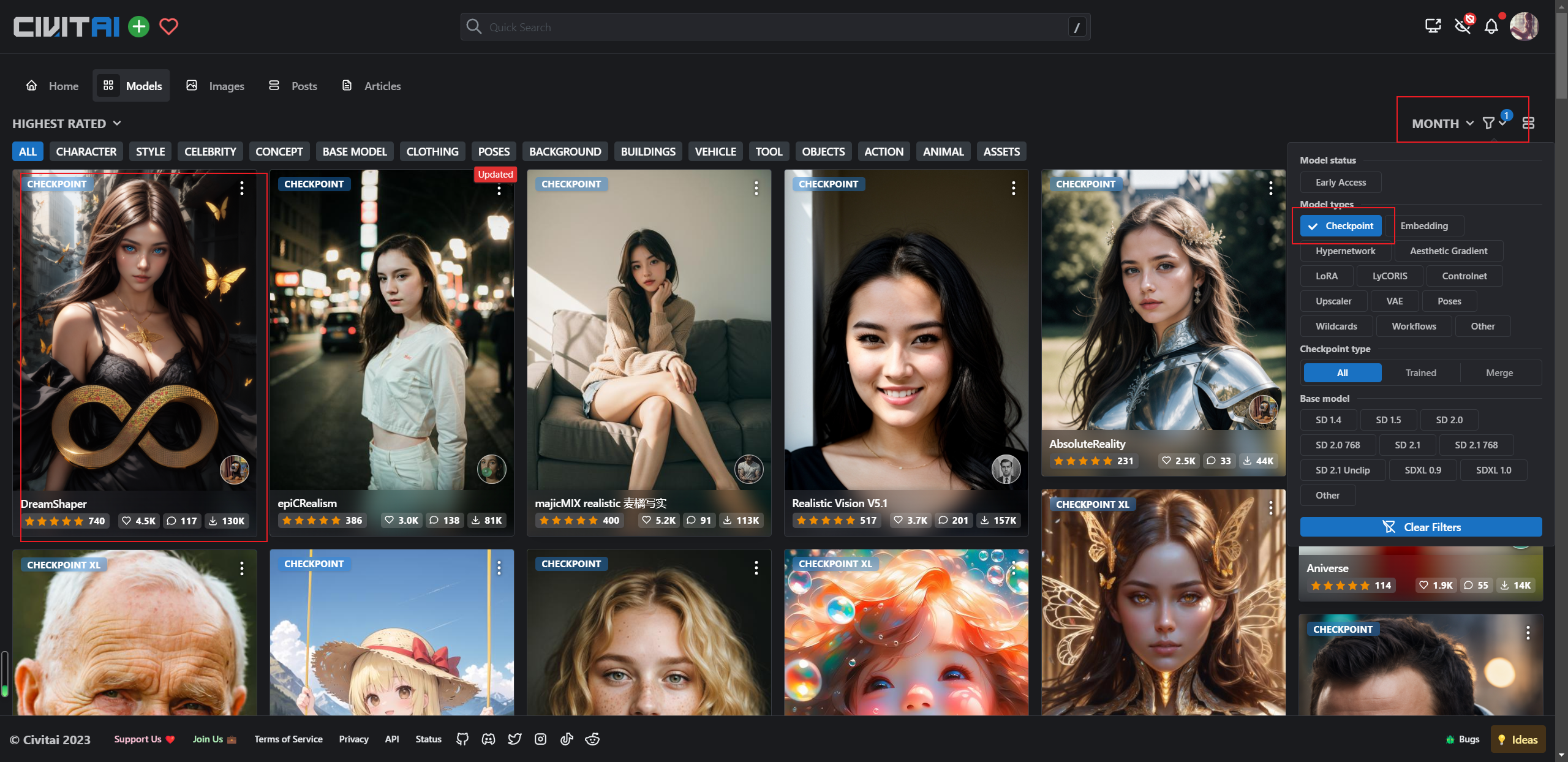
右边是筛选条件,筛选CheckPoint,就以第一个模型为例吧,第一个模型为DreamShaper,风格比较梦幻,点进去 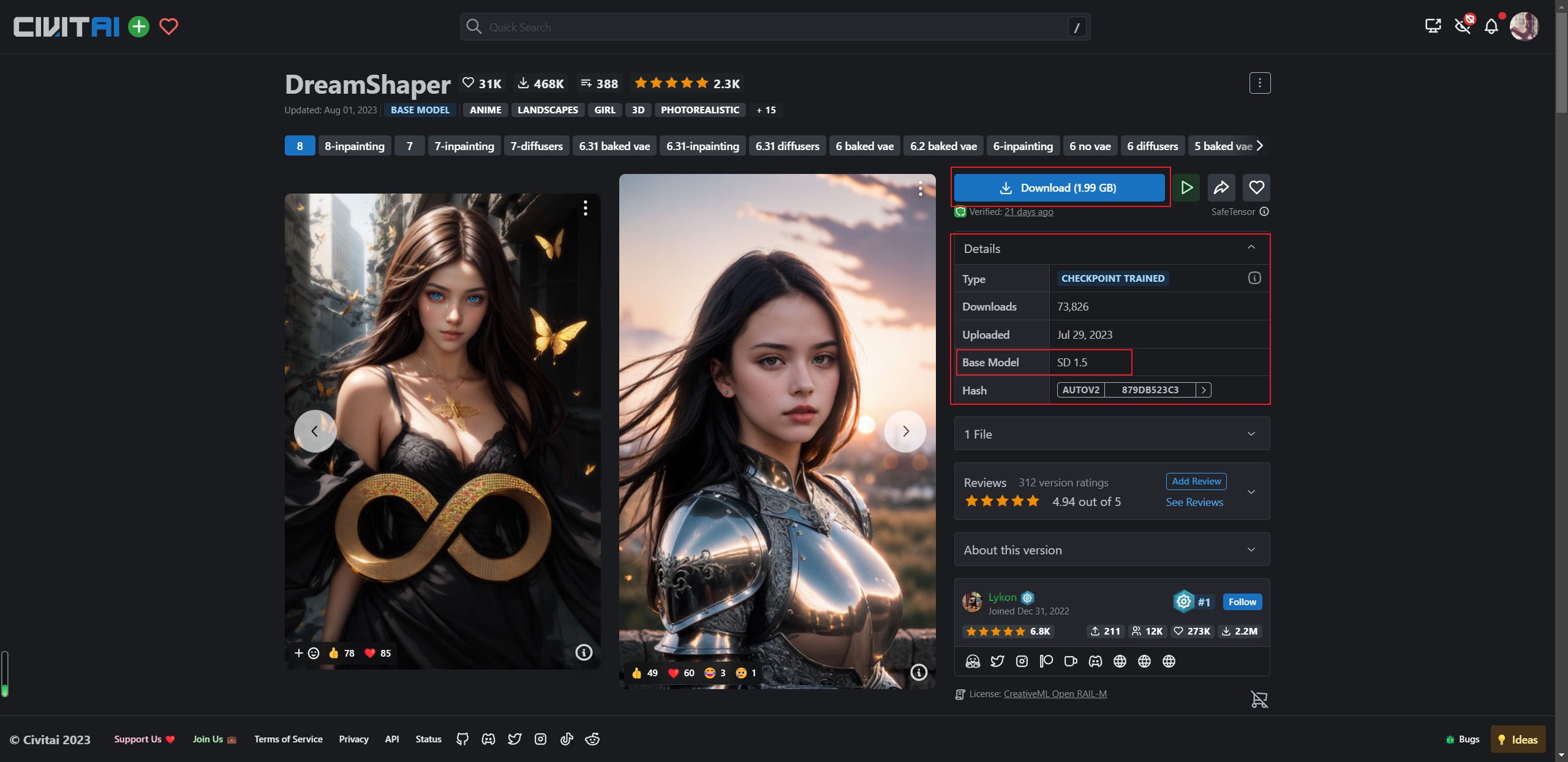
大大的蓝色按钮就是下载按钮,这里需要注意的是框中的明细,可以看到Base Model 为SD 1.5,与咱们安装的SD的版本是需要保持一致的,
(1)下载这个模型,需要魔法上网
(2)找到stable diffusion的项目目录,找到models文件夹,再找到Stable-diffusion文件夹,将下载下来的模型放进来,找到下图中的地方,点一下刷新的按钮,然后下拉框就会多一个咱们刚下载好的模型,选择咱们下载好的模型,会加载一段时间 
模型的使用
这里先介绍一下操作界面 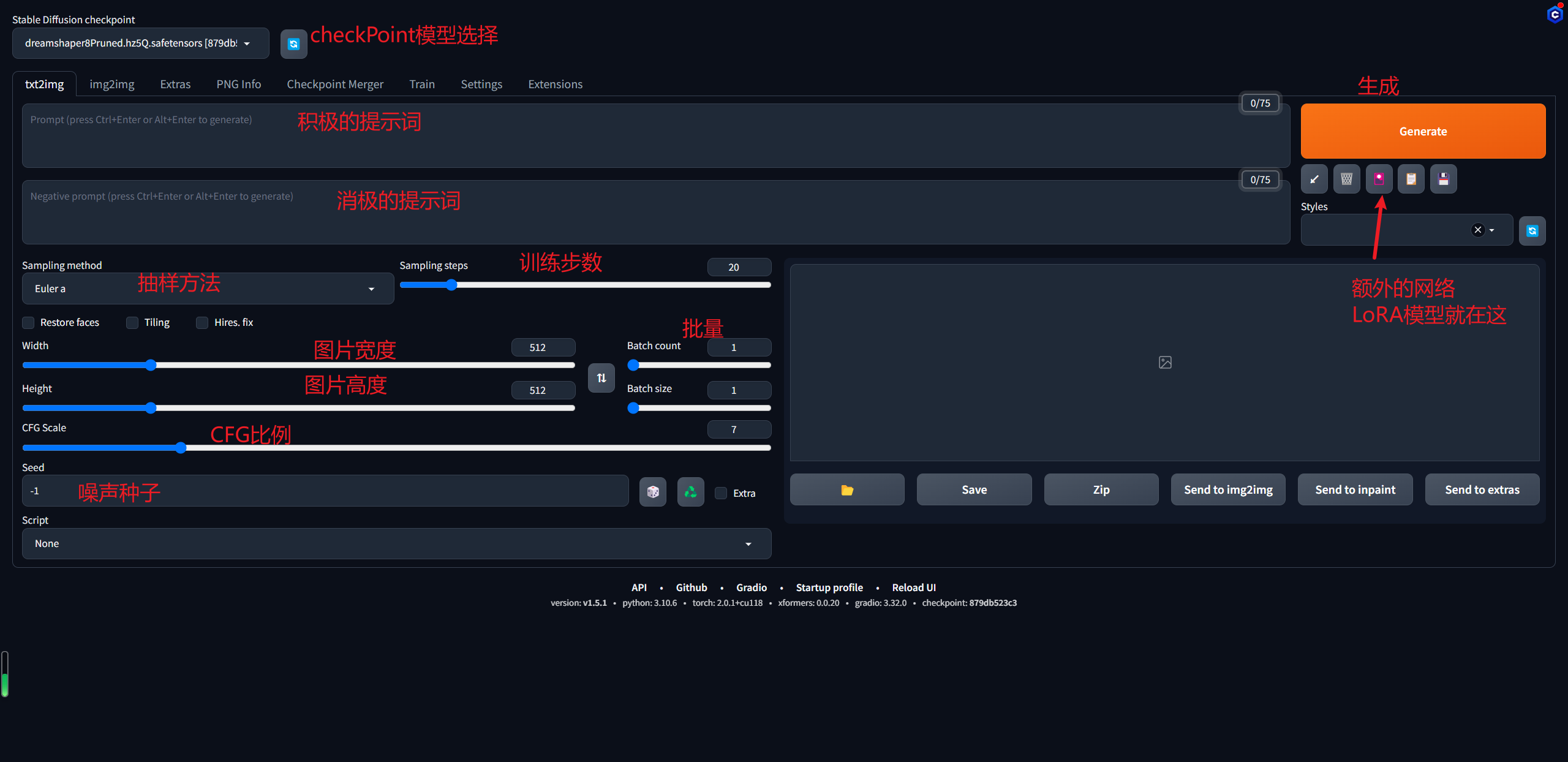
以第一张图片为例,可以点图片右下角的小叹号查看提示词是什么 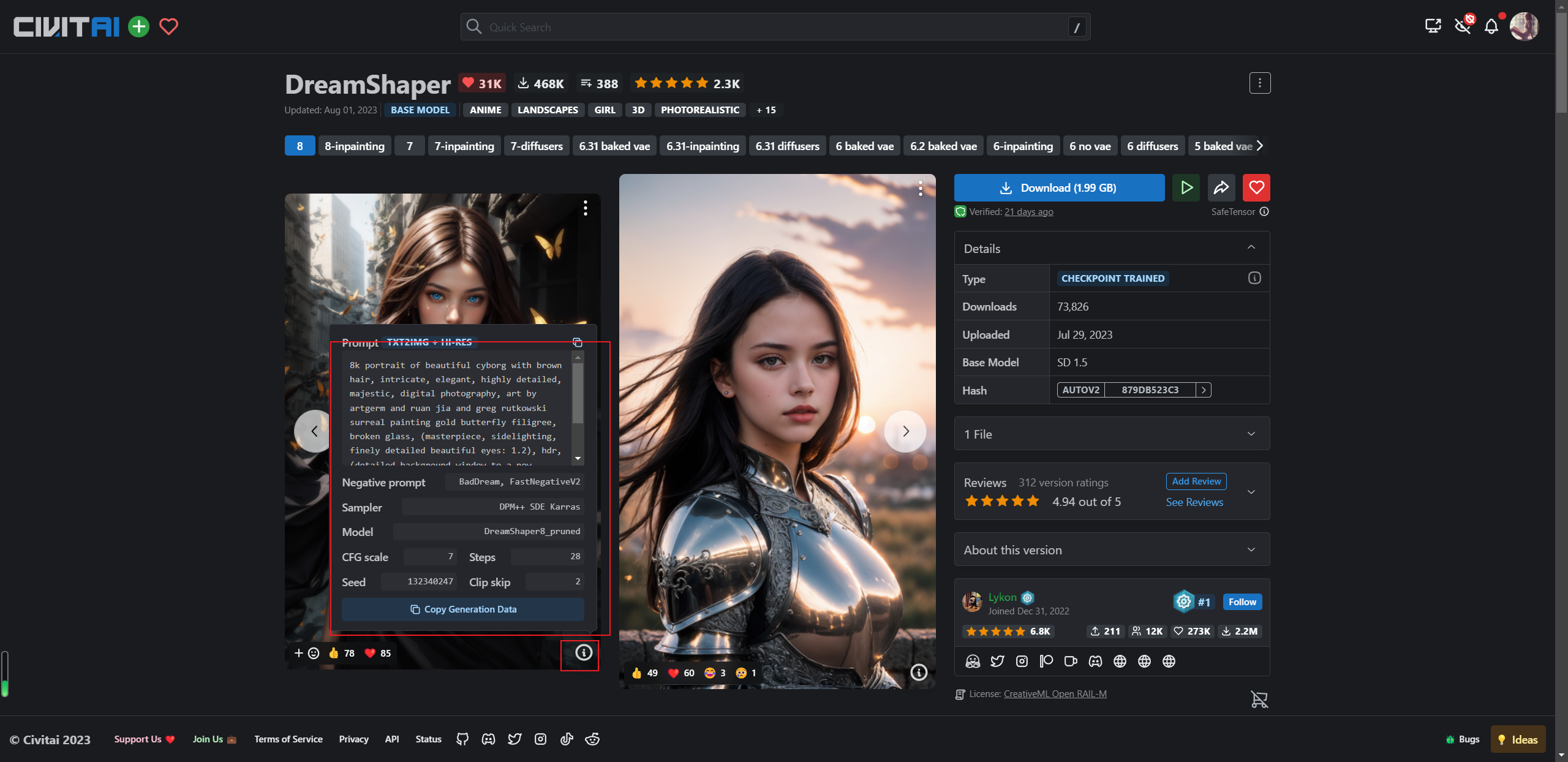
Stable Diffusion 关键词tag语法教程
分隔:不同的关键词tag之间,需要使用英文逗号,分隔,逗号前后有空格或者换行是不碍事的 ex:1girl,loli,long hair,low twintails(1个女孩,loli,长发,低双马尾)
混合:WebUi 使用 | 分隔多个关键词,实现混合多个要素,注意混合是同等比例混合,同时混。 ex: 1girl,red|blue hair, long hair(1个女孩,红色与蓝色头发混合,长发)
增强/减弱:有两种写法
第一种 (提示词:权重数值):数值从0.1~100,默认状态是1,低于1就是减弱,大于1就是加强 ex: ,(loli:1.21),(one girl:1.21),(cat ears:1.1),(flower hairpin:0.9)
第二种 (((提示词))),每套一层()括号增强1.1倍,每套一层[]减弱1.1倍。也就是套两层是1.1*1.1=1.21倍,套三层是1.331倍,套4层是1.4641倍。 ex: ((loli)),((one girl)),(cat ears),[flower hairpin]和第一种写法等价
所以还是建议使用第一种方式,因为清晰而准确
- 渐变:比较简单的理解时,先按某种关键词生成,然后再此基础上向某个方向变化。 [关键词1:关键词2:数字],数字大于1理解为第X步前为关键词1,第X步后变成关键词2,数字小于1理解为总步数的百分之X前为关键词1,之后变成关键词2
ex:a girl with very long [white:yellow:16] hair 等价为 开始 a girl with very long white hair 16步之后a girl with very long yellow hair
ex:a girl with very long [white:yellow:0.5] hair 等价为 开始 a girl with very long white hair 50%步之后a girl with very long yellow hair
- 交替:轮流使用关键词 ex:[cow|horse] in a field比如这就是个牛马的混合物,如果你写的更长比如[cow|horse|cat|dog] in a field就是先朝着像牛努力,再朝着像马努力,再向着猫努力,再向着狗努力,再向着马努力
常用提示词
提示词
Prompt
(masterpiece:1.0), (best quality:1.0), (ultra highres:1.0) ,(8k resolution:1.0),(realistic:1.0),(ultra detailed1:0), (sharp focus1:0), (RAW photo:1.0)
1 girl,detailed beautiful skin, kind smile, solo, absurdres, detailed beautiful face, petite figure, detailed skin texture, pale skin, thigh gap, detailed hair, random hair style, detailed eyes, glistening skin,portrait photo,
(short sleeve shirts:1.1),(uniform:1.1),(pantyhose:1.2),(pleated skirt:1.1),ear rings ,futuristic, studio, (white background:1.4),
Negative prompt
(Nsfw:1.4),
(Easy Negative:1.4), (worst quality: 1.4), (low quality: 1.4), (normal quality: 1.4),
lowers,monochrome,grayscales,skin spots, acnes, skin blemishes, age spot,6 more fingers on one hand,deformity, bad legs, error legs, bad feet, malformed limbs, extra limbs,将积极的提示词,消极的提示词,噪声种子等信息复制到对应的框中点击生成,可以看到生成出来的图像可以说是完全对不上,这里是因为图像的大小,以及对应的LoRA模型咱都没对上哈 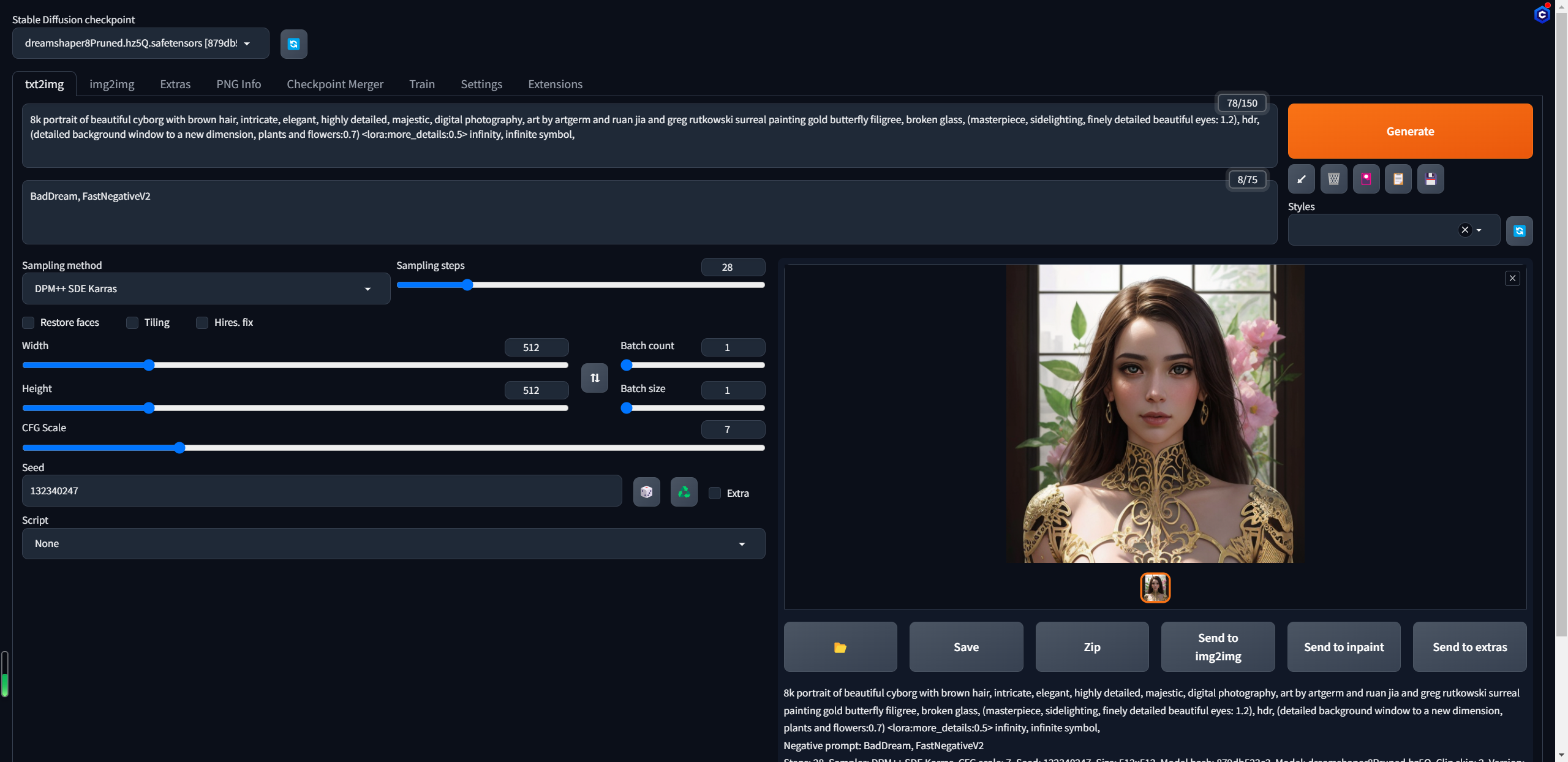
LoRA模型介绍
什么是LoRA模型?
打个比方,有一个汉堡店,有个标准套餐,鸡肉火腿汉堡,甜辣味的,有一家人,到汉堡店吃饭,大人喜欢点标准套餐加辣,加番茄片,火腿片。小孩点标准套餐,加糖,加沙拉。这个加的额外的调料就是LoRA模型。
找一个LoRA模型 more_details,可以看到相较于CheckPoint模型,LoRA模型就小很多了,只有10M不到 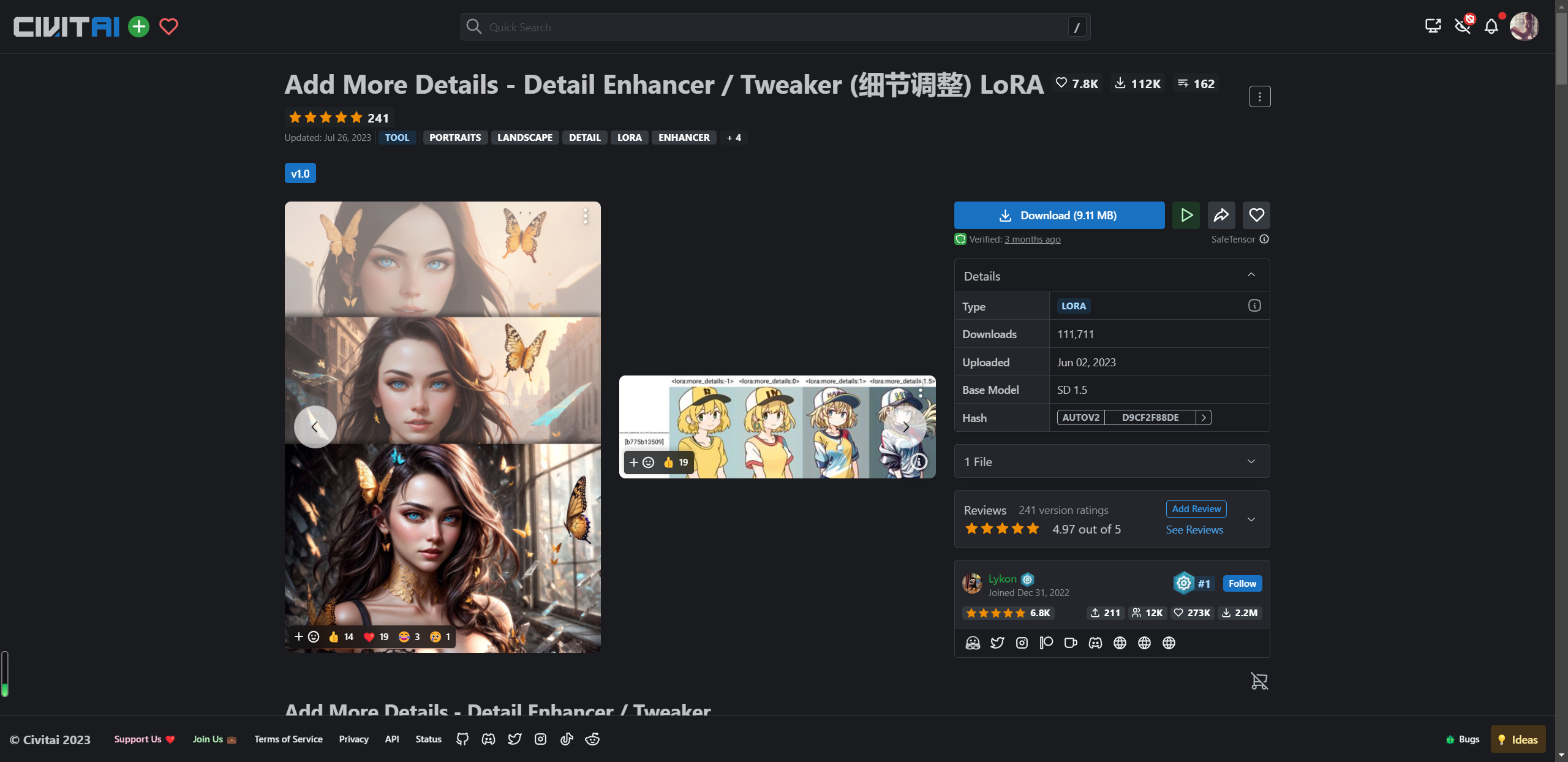 将下载下来的LoRA模型放到项目目录的models下的Lora目录,进入到界面,刷新一下
将下载下来的LoRA模型放到项目目录的models下的Lora目录,进入到界面,刷新一下 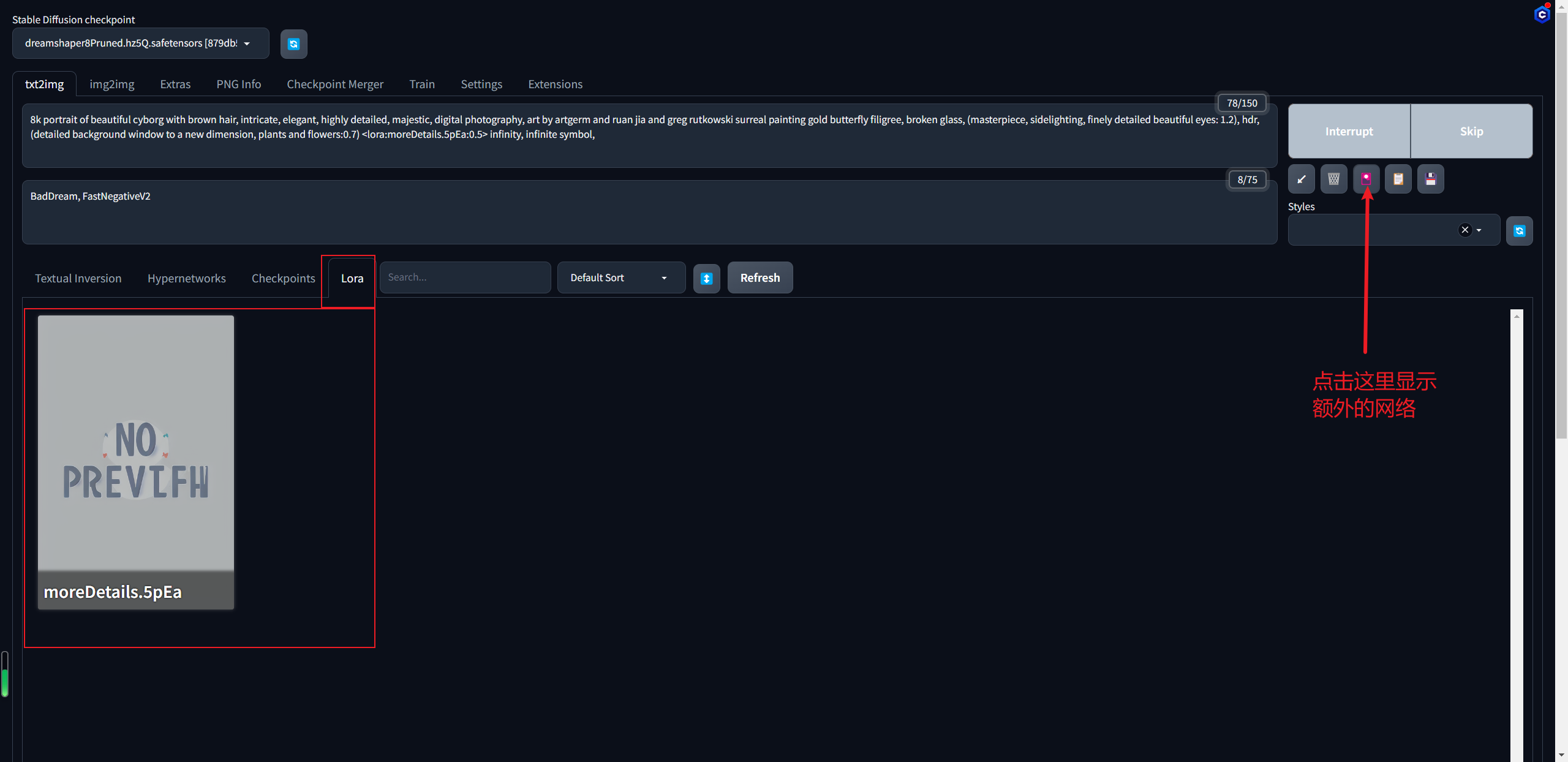
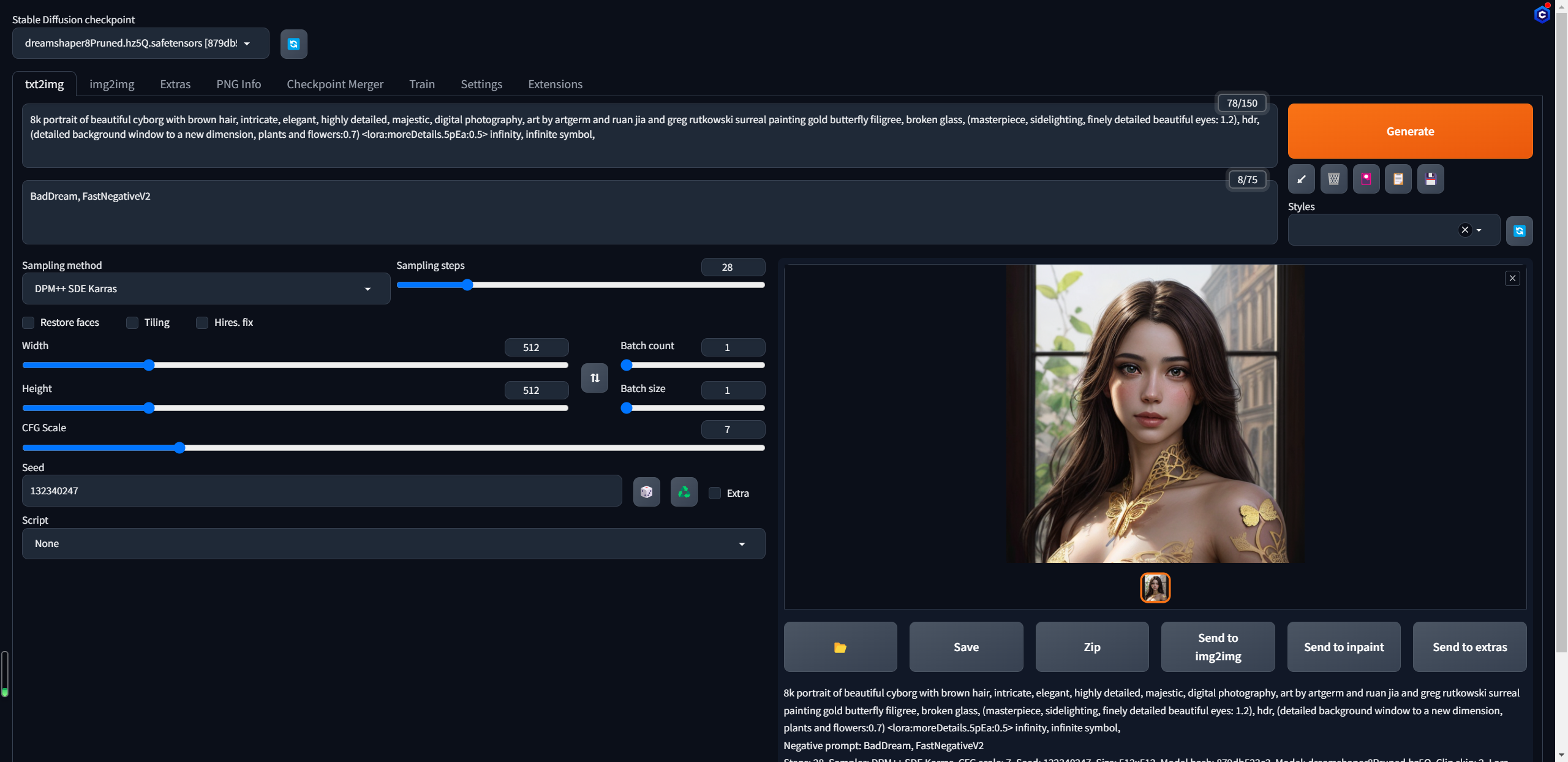 可以看到已经有提示词里的蝴蝶了,只不过是衣物上的装饰品
可以看到已经有提示词里的蝴蝶了,只不过是衣物上的装饰品
这里注意,由于咱们自己下载的LoRA模型安装之后名字叫做moreDetails.5pEa,所以上边提示词也要相应的改变一下,有些LoRA模型不需要触发词就能对结果产生影响,还有一些LoRA模型是需要一些触发词才能生效,例如,墨心的LoRA模型 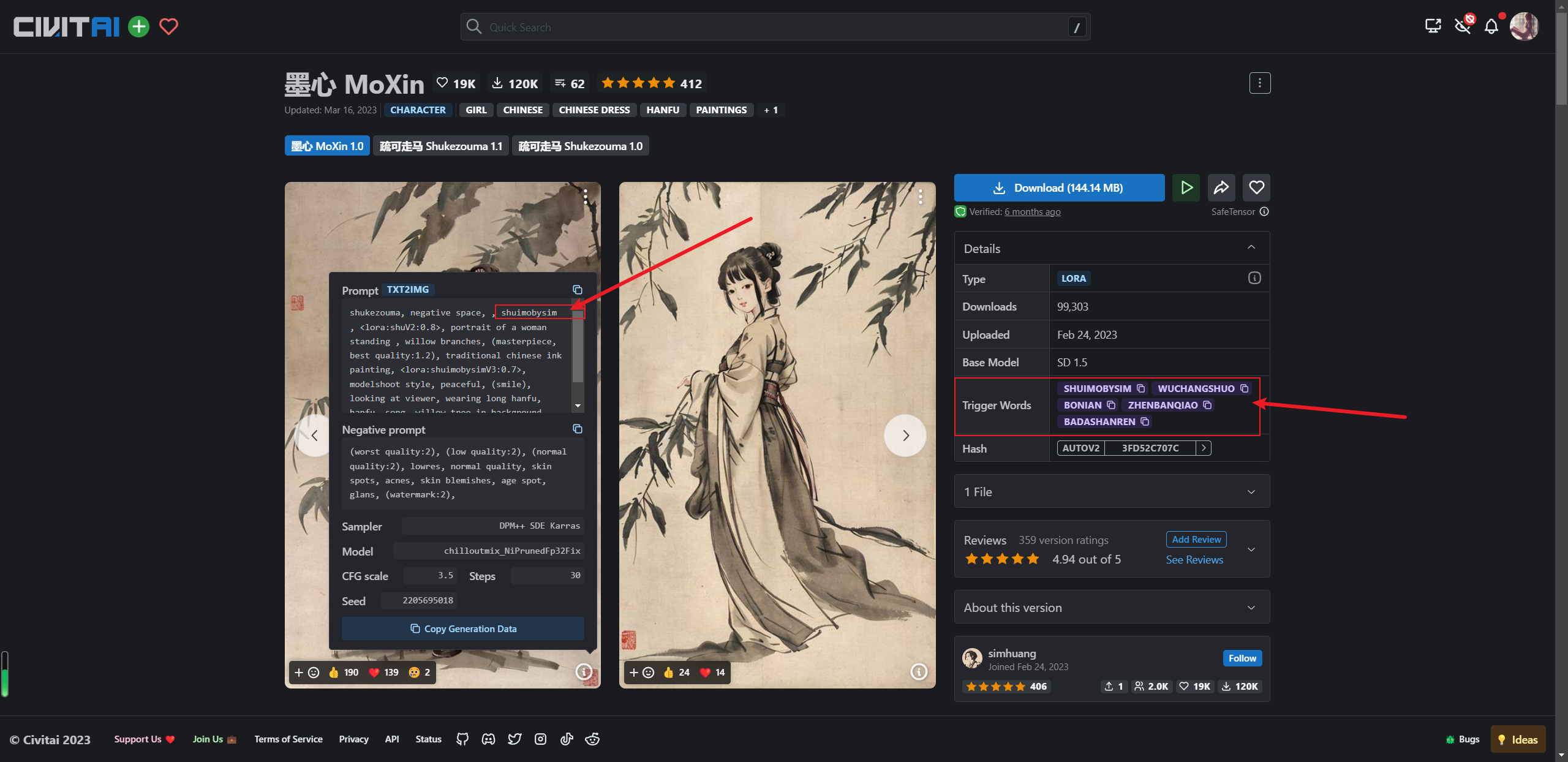 所以综上,光靠提示词想弄出和作者一模一样的还是很难的,所以缺乏控制性,这是我们所不能忍受的
所以综上,光靠提示词想弄出和作者一模一样的还是很难的,所以缺乏控制性,这是我们所不能忍受的
ControlNet介绍
ControlNet的基本功能
安装ControlNet
首先安装opencv-python库
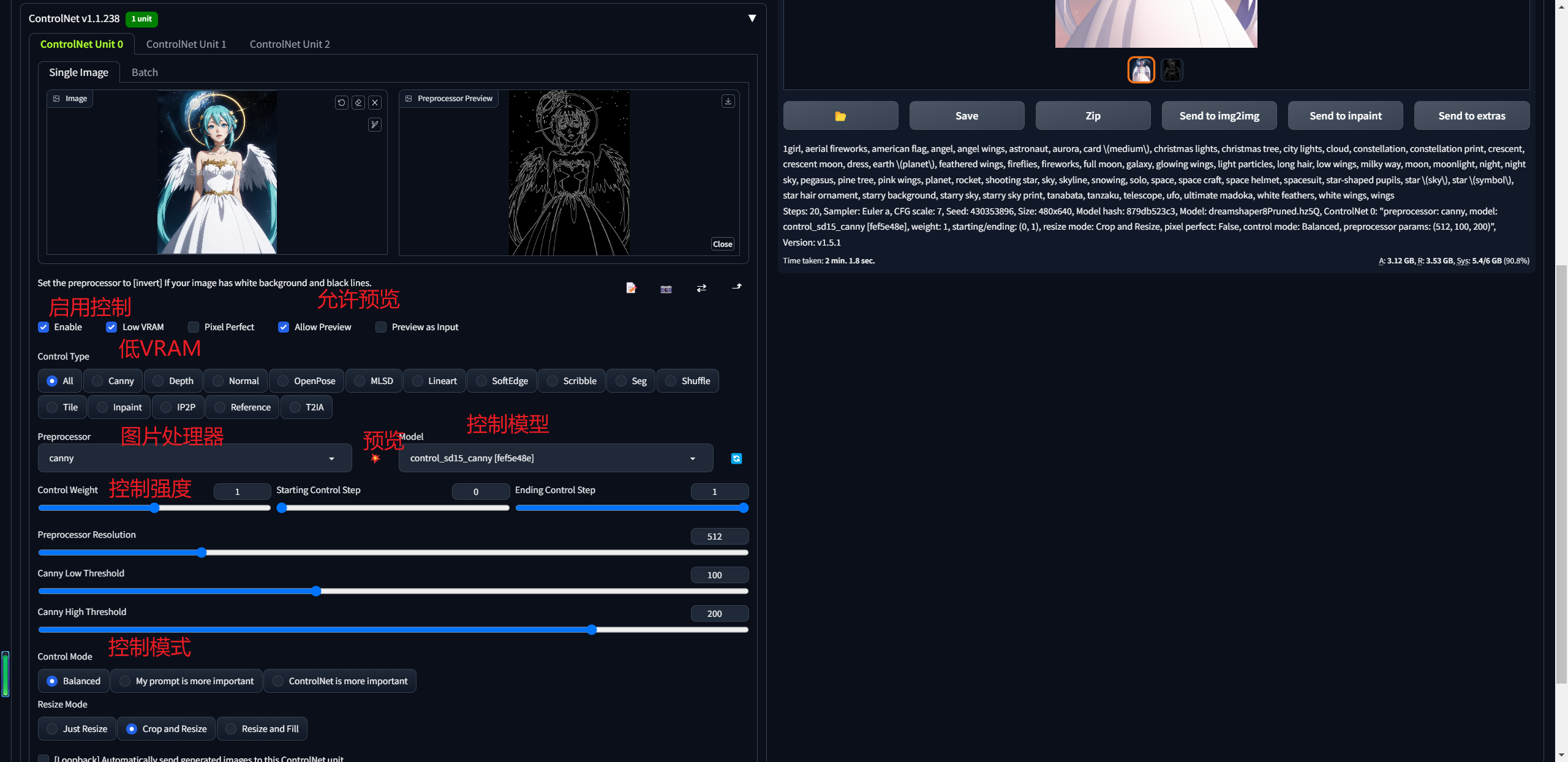
pip install opencv-python然后启动stable-diffusion-webui打开Extensions选项卡使用Install from URL将下边的地址拷贝https://github.com/Mikubill/sd-webui-controlnet.git 点击install稍等片刻,下边提示installed,点击Reload UI 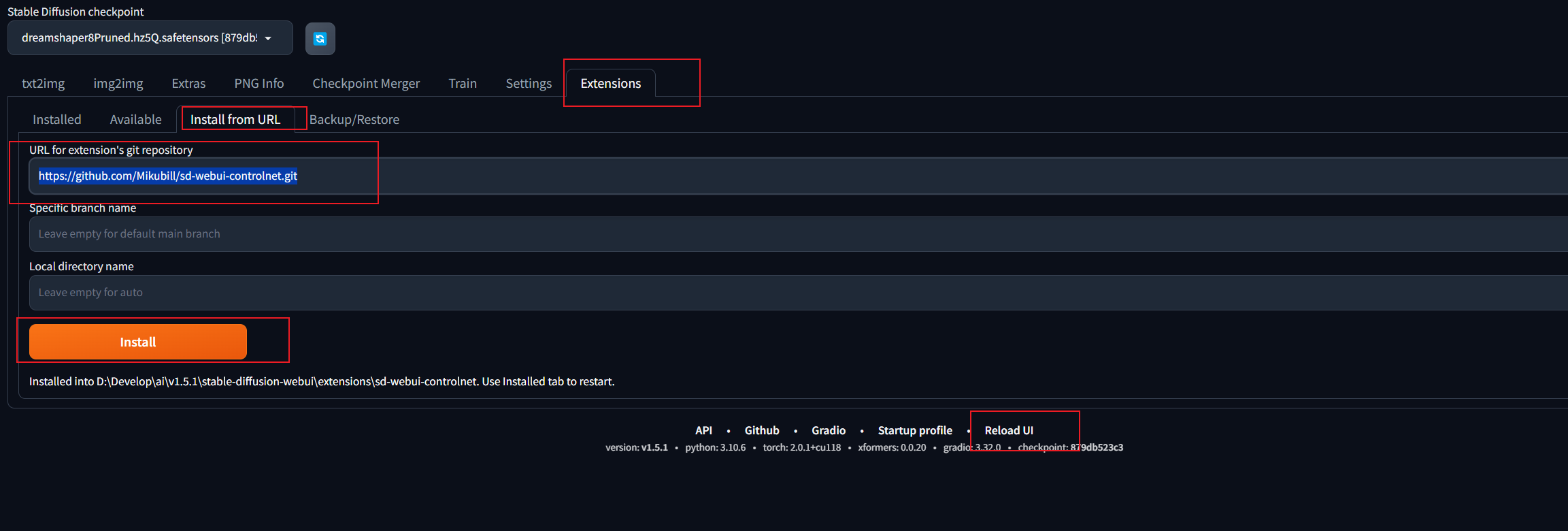 此时主界面多了一个ControlNet选项卡
此时主界面多了一个ControlNet选项卡  从huggingface下载控制计算模型
从huggingface下载控制计算模型https://huggingface.co/lllyasviel/ControlNet/tree/main/models 模型有些多,建议全部下载 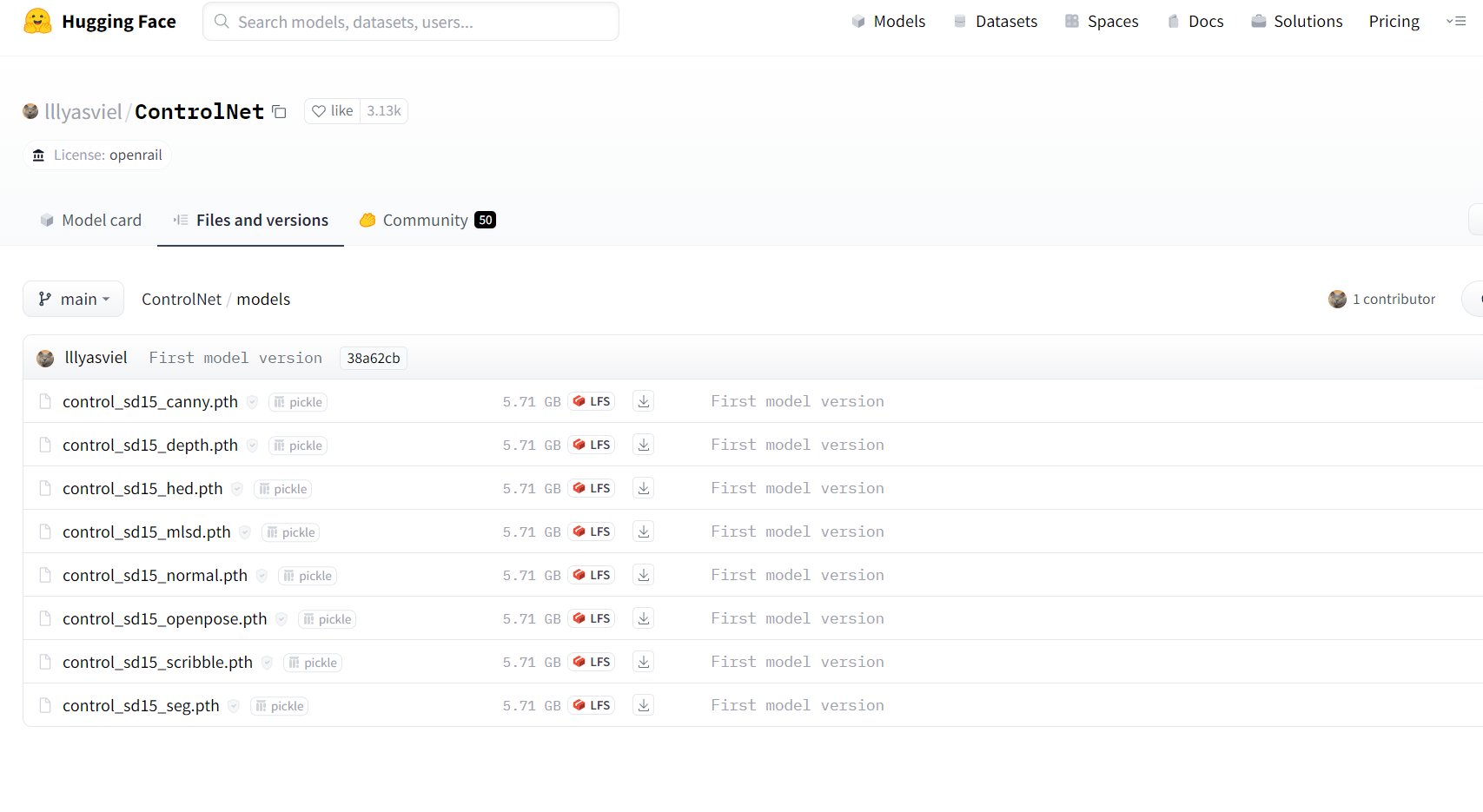
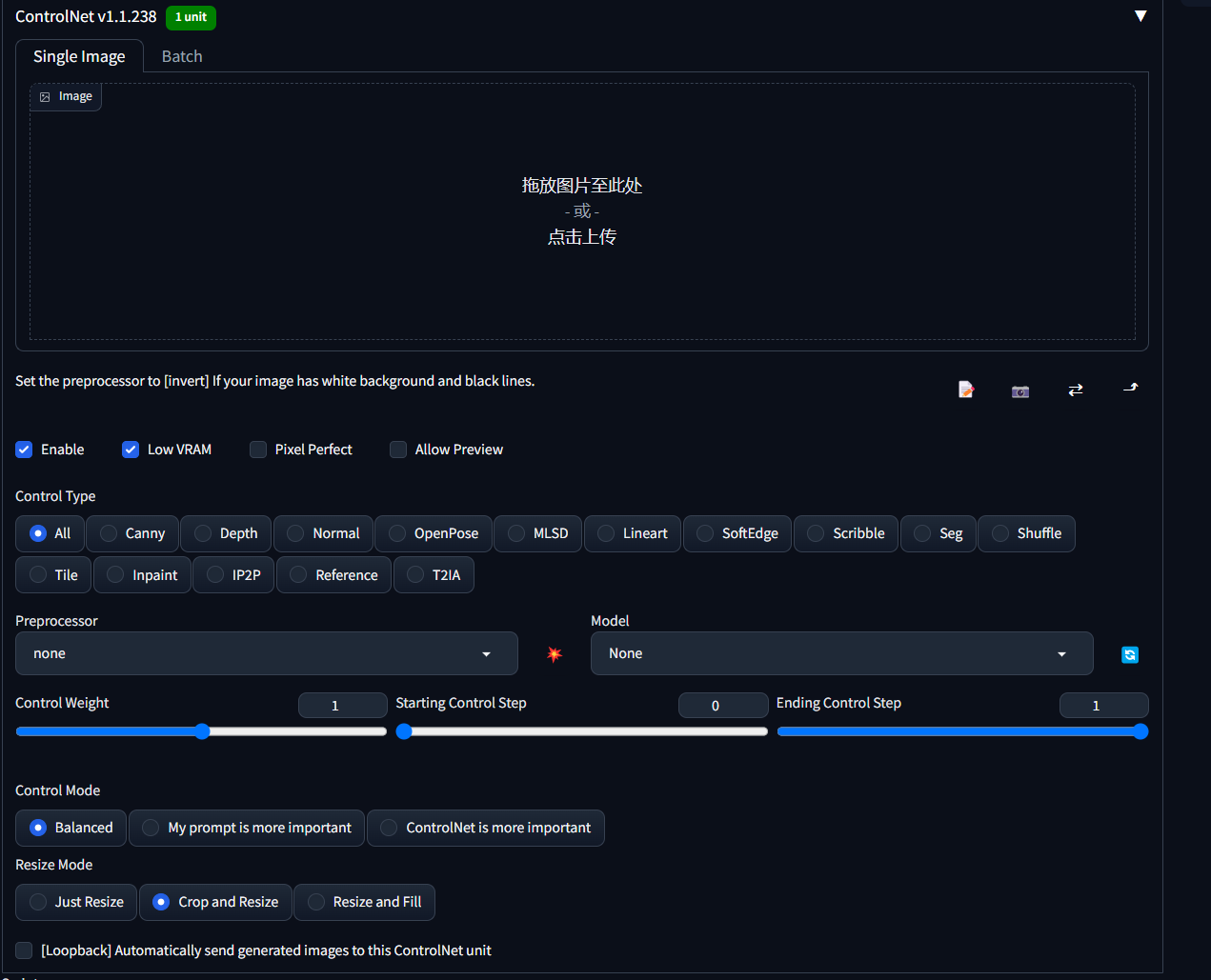
canny模型
用来进行边缘检测获取线稿的模型,可以处理人物、动物等等。图片放入img2img获取图片的提示词 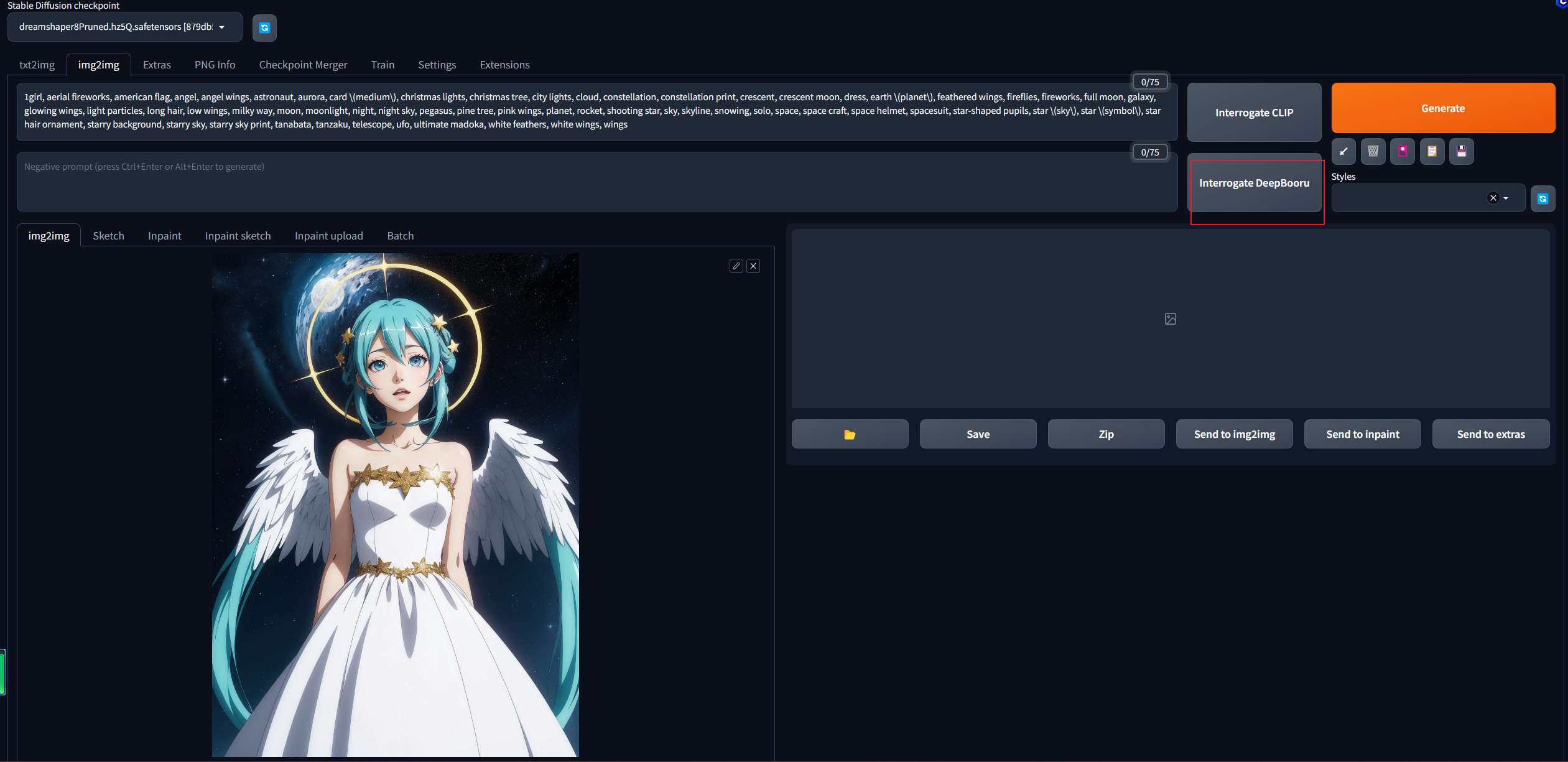 将提示词复制到文生图,点击生成,可以看到,生成的图片基本被上传的图片控制了
将提示词复制到文生图,点击生成,可以看到,生成的图片基本被上传的图片控制了 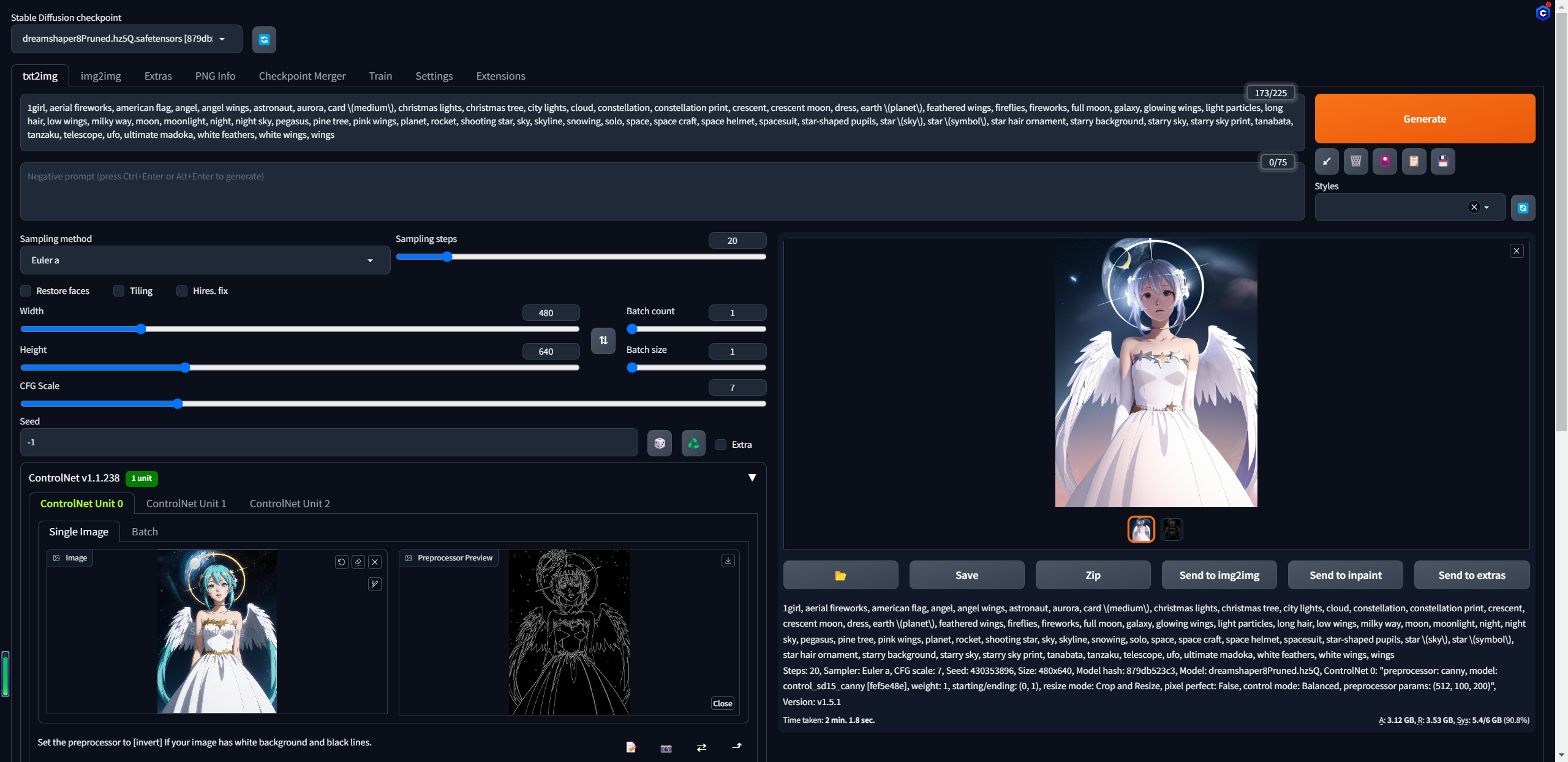
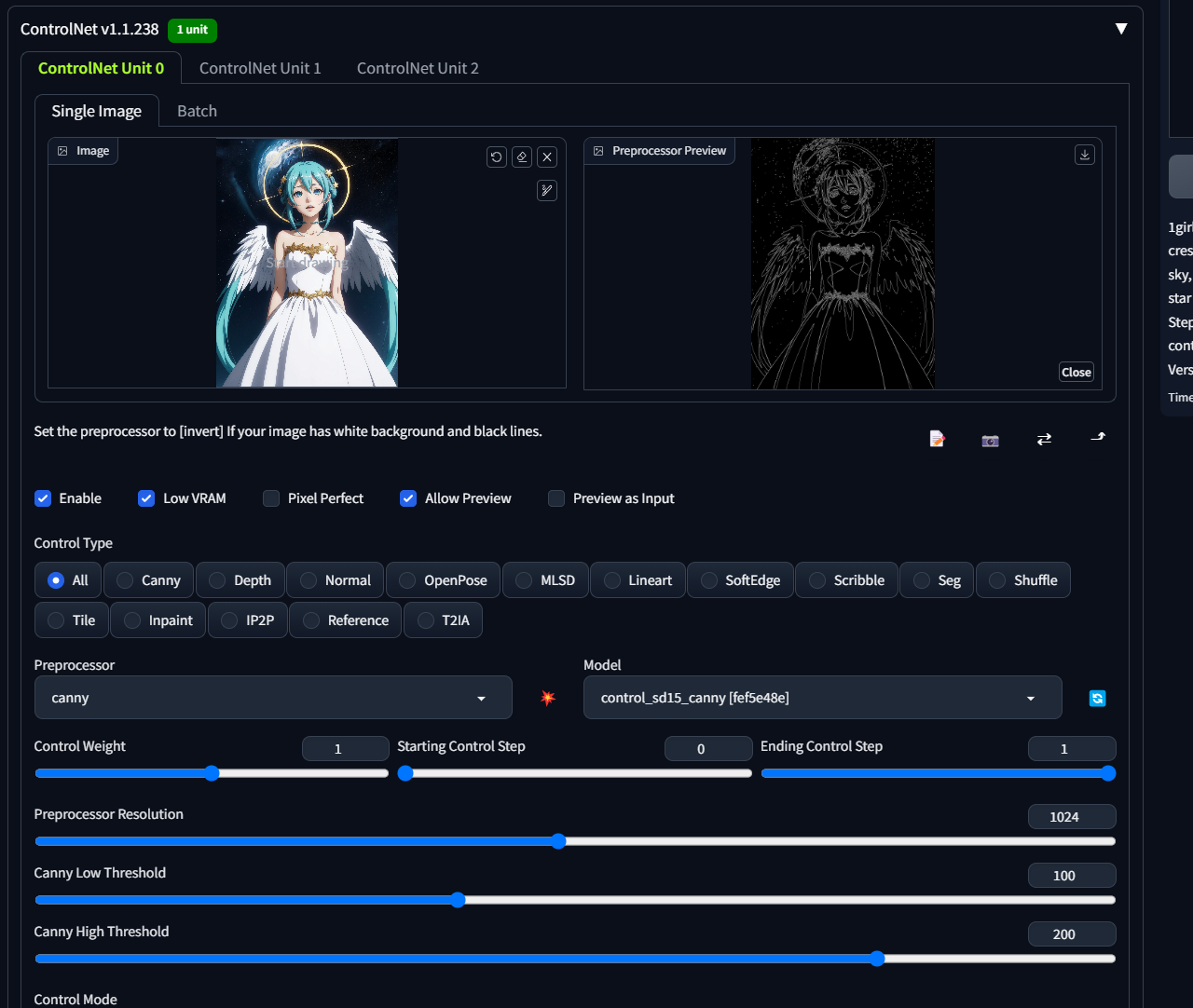 当调大取样分辨率之后,可以发现线条更加的细腻了
当调大取样分辨率之后,可以发现线条更加的细腻了
softedge_hed模型
是一种利用色差取出轮廓线的技术,比较适合用来分析边缘不清楚的图像,比如油画或边缘较为凌乱的照片。常用于风格转换 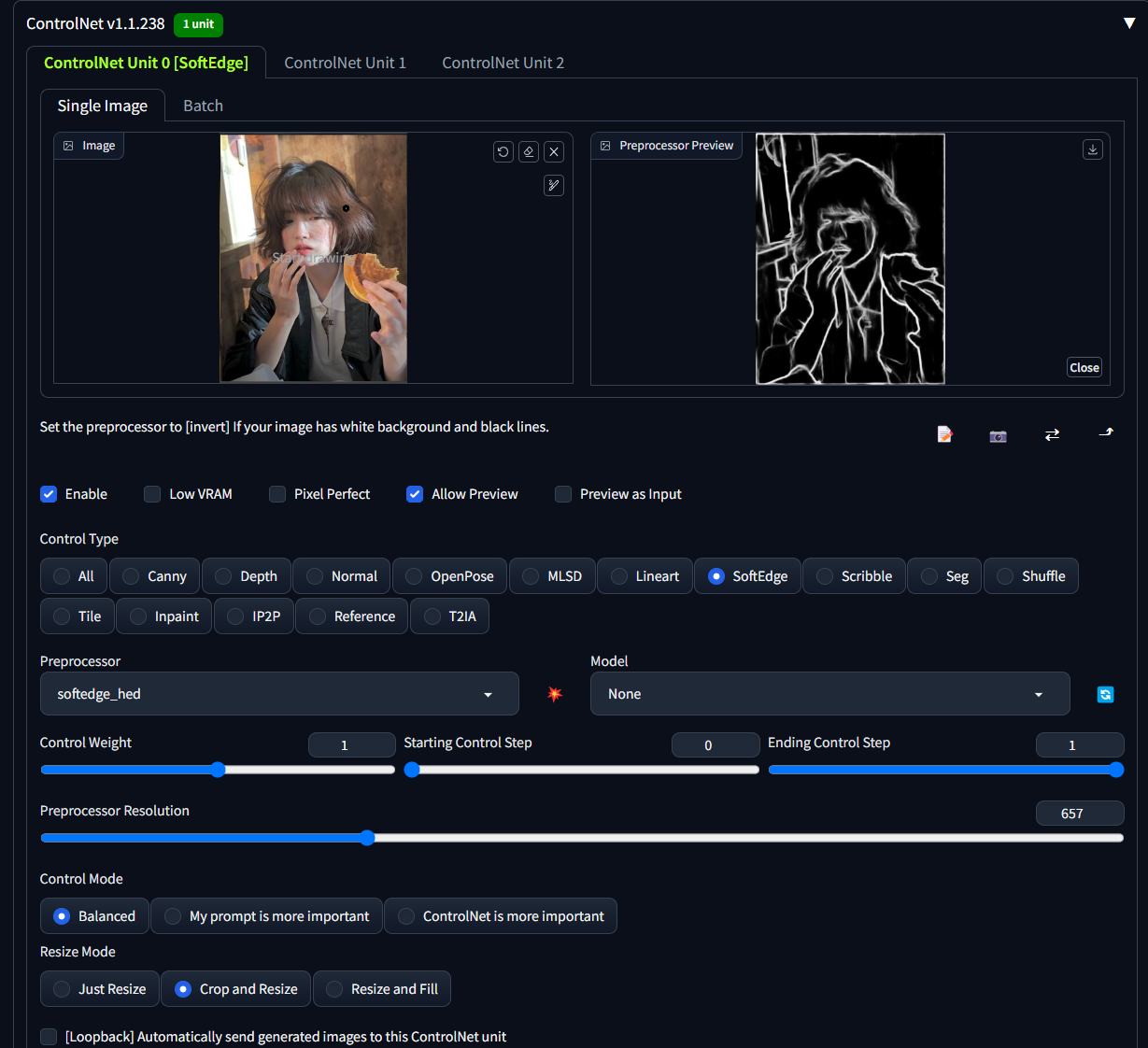
openpose模型
用来识别人类的骨架姿势模型,使用率很高 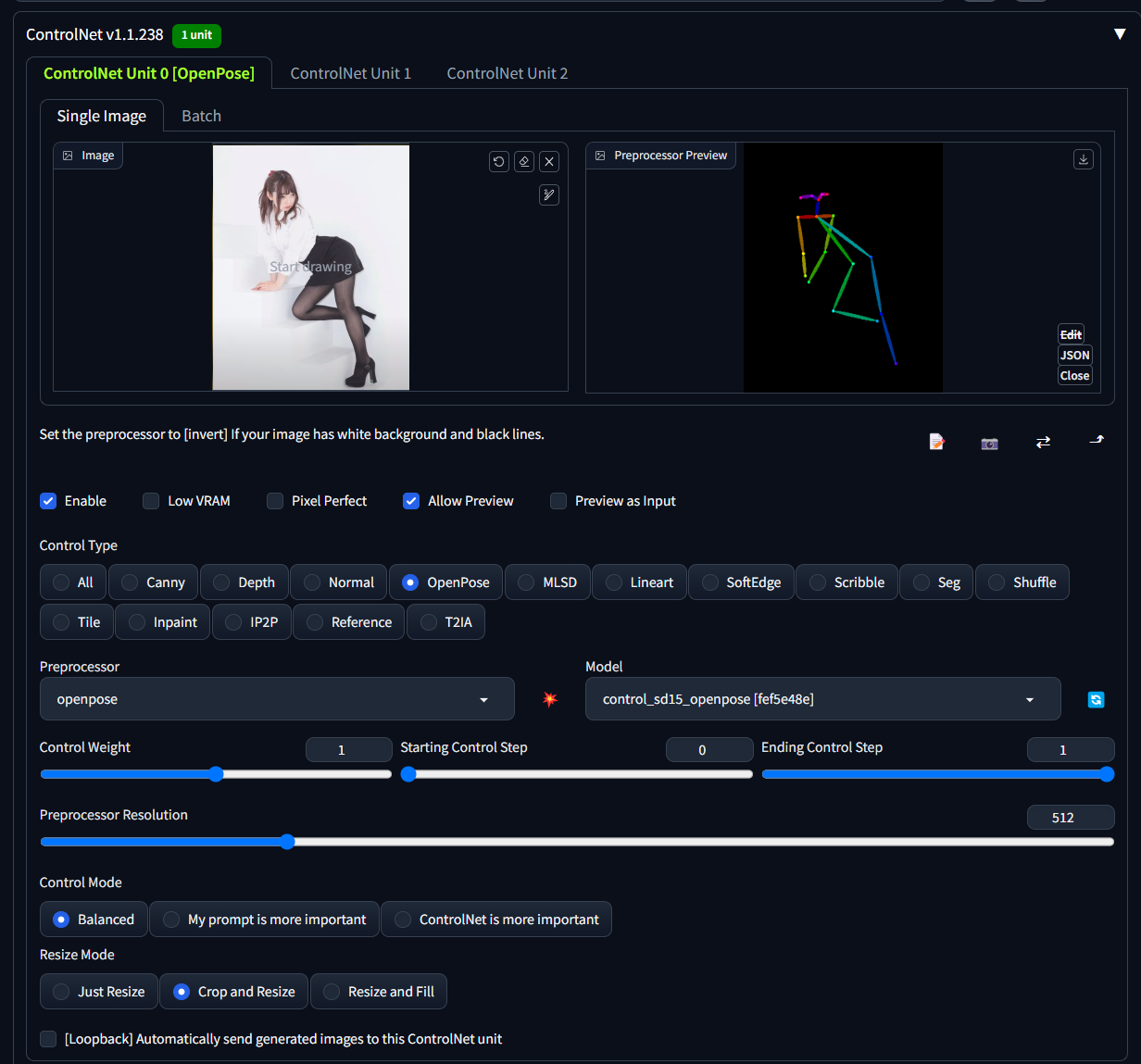
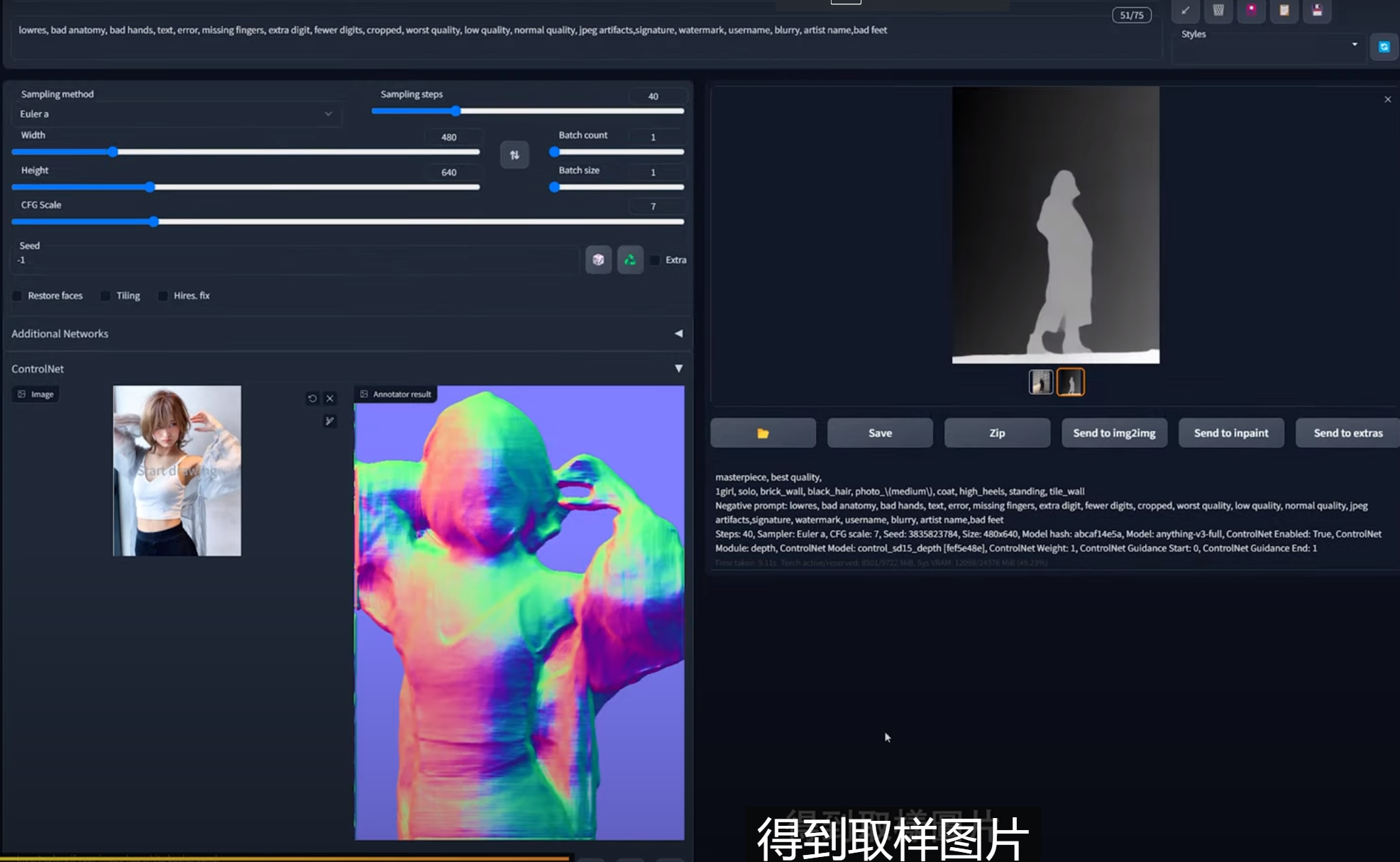
depth模型
用亮度表示图片深度的模型,常用来构建场景比较大的图形 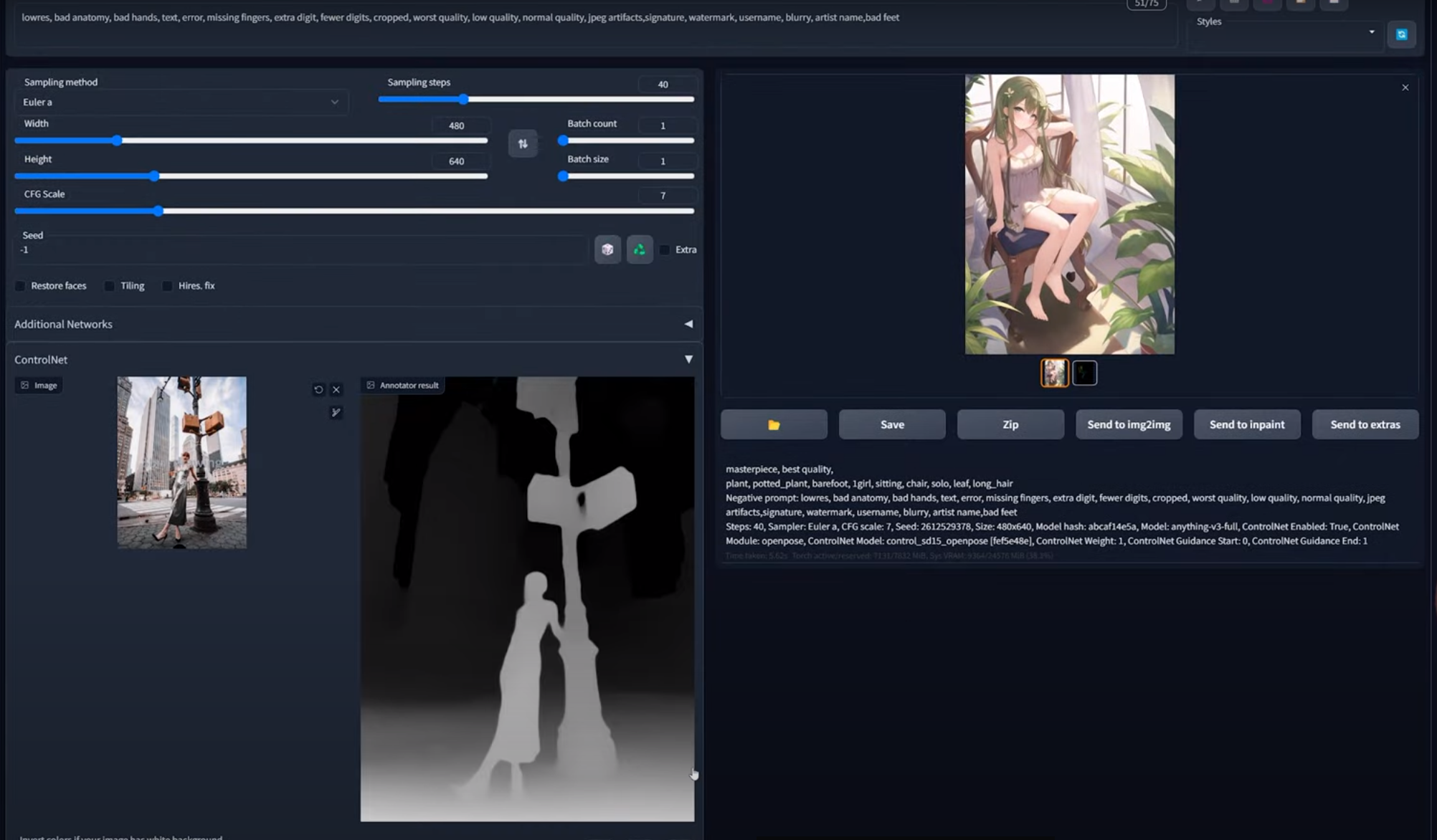

normal_midas模型
使用RGB数值记录向量的技术,3D建模领域经常使用
 |  |
|---|
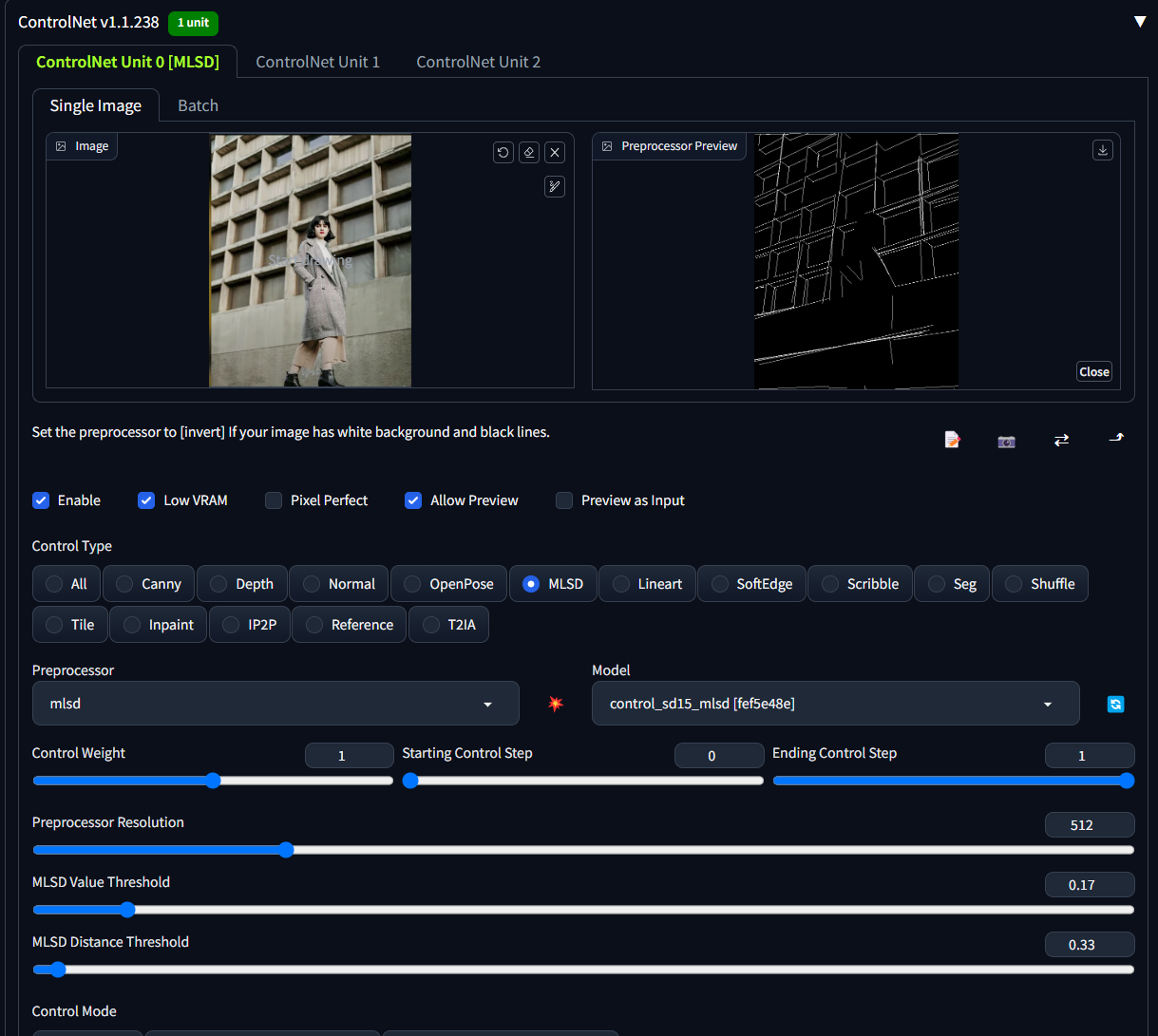
MLSD模型
用来处理场景直线较多的场景 
 |  |
|---|
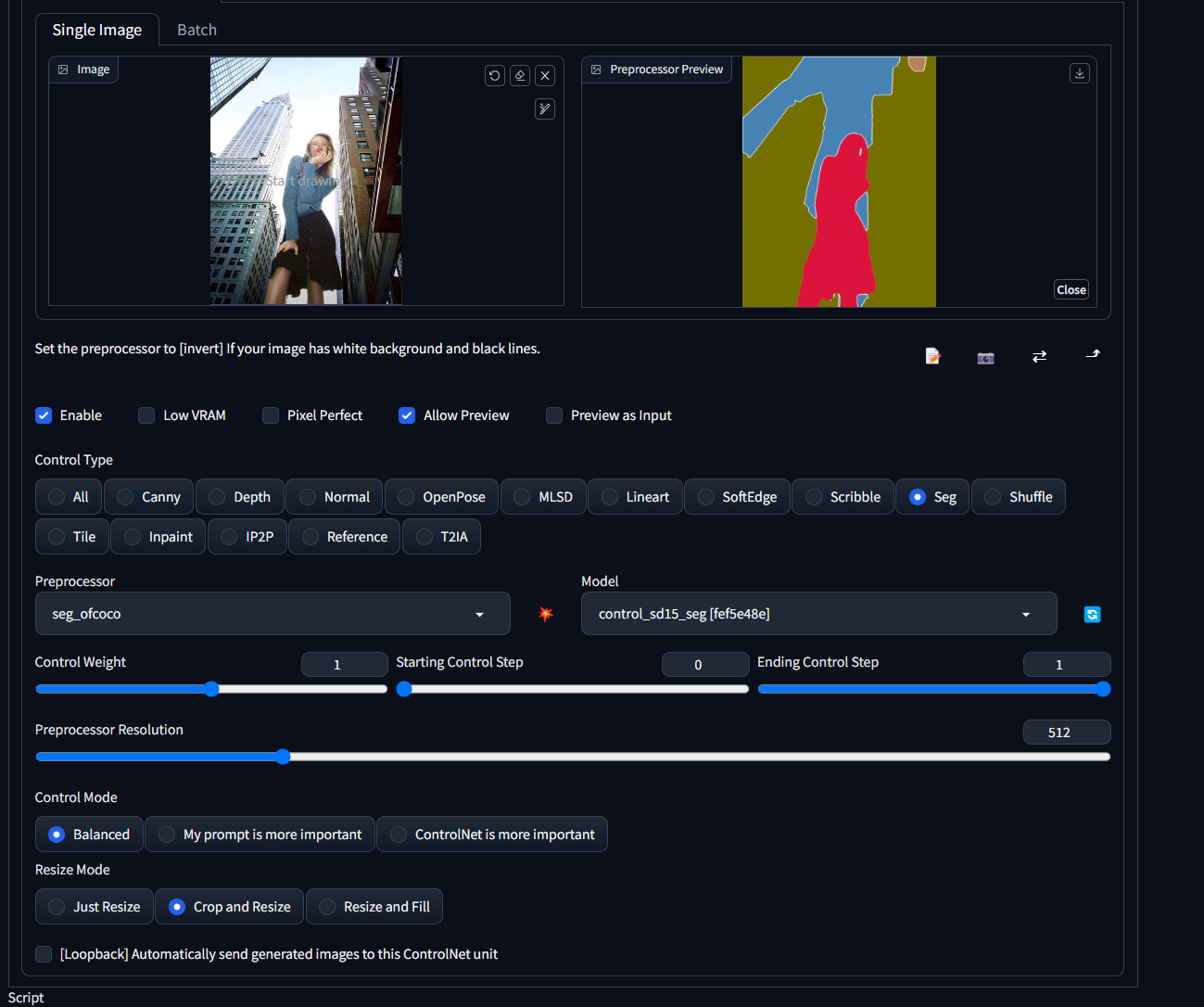
Seg模型
用颜色区分物品的模型,常用于建筑物品分割 
 |  |
|---|
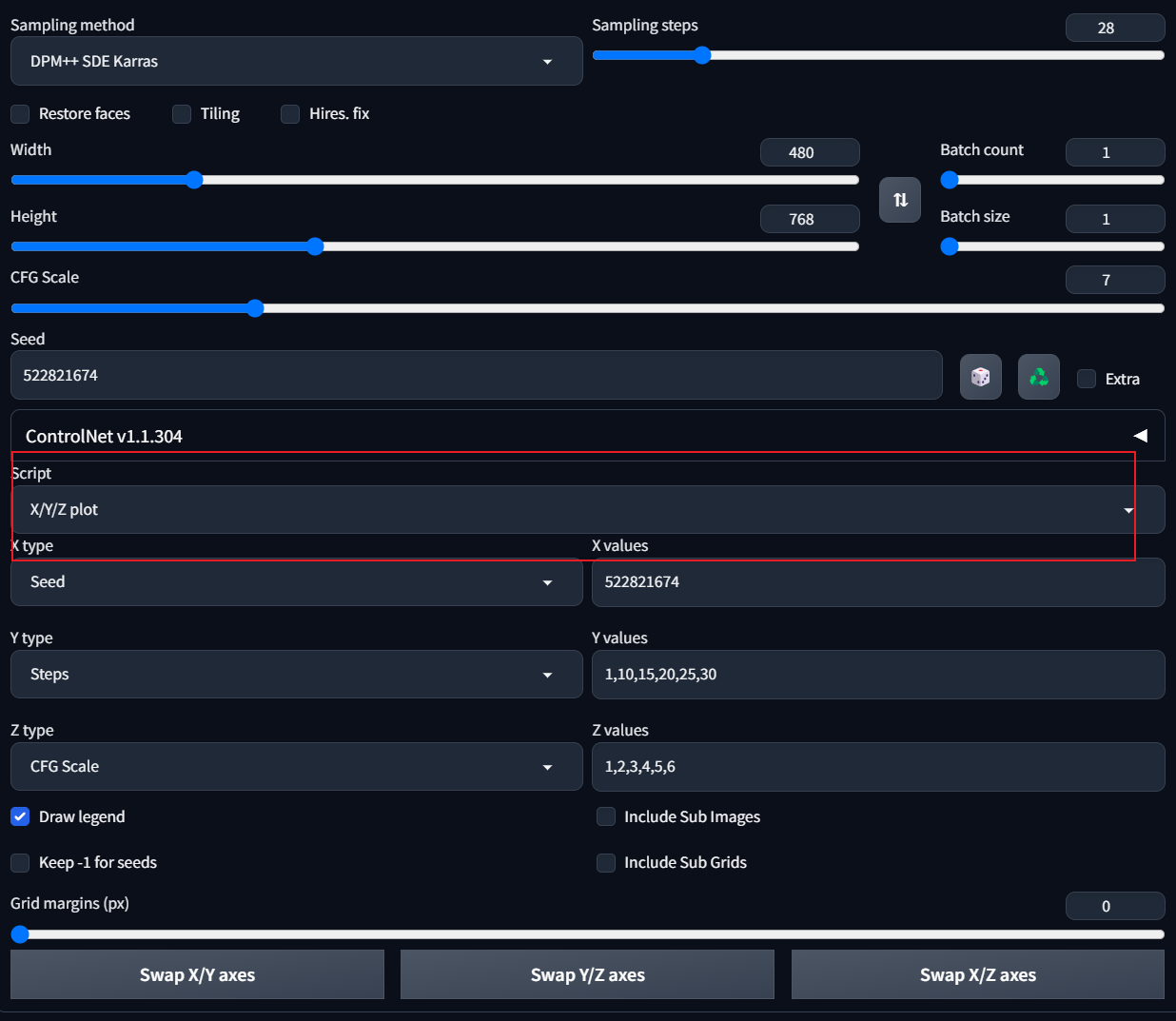
Script之x/y/z plot介绍
SD与GPT相结合
首先给大家看一个一些截图 
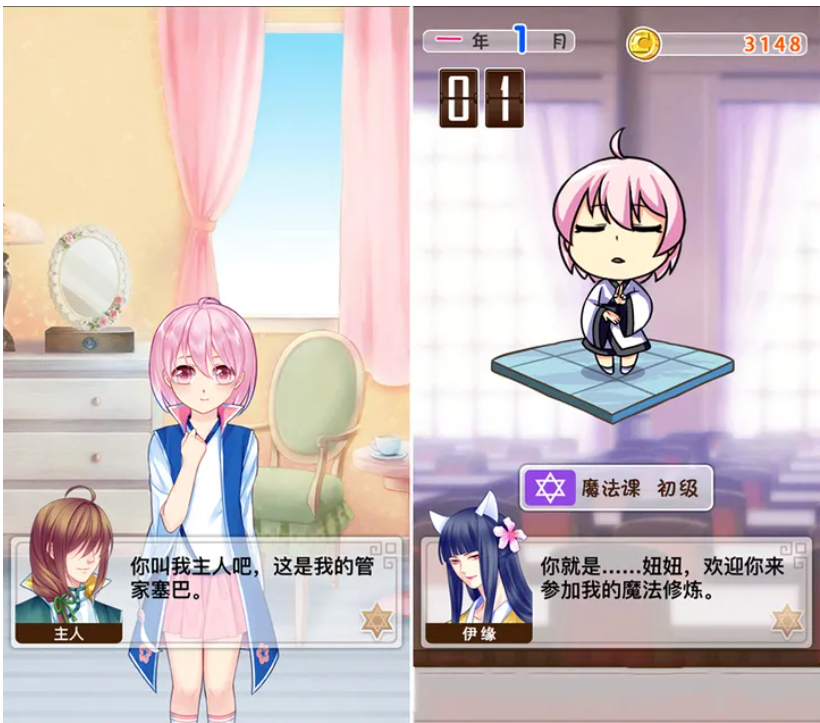
类似角色扮演养成类的游戏相信大家都见过,GPT就可以续写游戏的脚本,故事情节,而SD则可以根据脚本和情节,快速的生成图片
最后给大家分享一下优秀的博主