大模型入坑指南(LangChain篇)
开篇
当ChatGPT和GPT-4横空出世时,全世界都为之震撼——通用人工智能的奇点,真的即将来临了吗?作为研发人员,我们惊喜地发现,最前沿的AI技术与实际应用之间的距离,竟然如此之近!更为关键的是,ChatGPT不仅是一场技术革命,它还能为企业提供便捷的服务。在ChatGPT这样的模型基础上开发的应用,正在帮助企业优化客户服务、提升服务质量、加强市场营销、优化产品设计、改进供应链管理等。大语言模型的落地场景,几乎覆盖了各行各业的方方面面。
什么是大语言模型
大语言模型是一种人工智能模型,通常使用深度学习技术,比如神经网络,来理解和生成人类语言。这些模型的“大”在于它们的参数数量非常多,可以达到数十亿甚至更多,这使得它们能够理解和生成高度复杂的语言模式。 你可以将大语言模型想象成一个巨大的预测机器,其训练过程主要基于“猜词”:给定一段文本的开头,它的任务就是预测下一个词是什么。模型会根据大量的训练数据(例如在互联网上爬取的文本),试图理解词语和词组在语言中的用法和含义,以及它们如何组合形成意义。它会通过不断地学习和调整参数,使得自己的预测越来越准确。
本次介绍使用的开发框架为LangChain,让我们从0到1的开始对大模型开发进行全面的认识
系统安装和快速入门
python环境准本
python版本最好是3.8及以上,建议使用miniConda安装和管理python版本及软件安装包,防止环境问题带来的影响
一些简单的Conda命令
# 列出已经安装的环境
conda info --env
# 创建一个python3.12的环境
conda create --name langchain_py3.12 python=3.12
# 激活环境
conda activate langchain_py3.12
# 删除环境
conda remove -n langchain_py3.12 --all通过miniConda创建好一个python3.12版本的python环境
LangChain安装
本次介绍的为v0.3版本
LangChain分为LangChain核心依赖,以及第三方依赖
# 核心依赖
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple langchain
# 三方依赖
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple langchain-community
# 如果使用百度的千帆,需要额外安装qianfan包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple qianfanHello Word
import os
os.environ["QIANFAN_AK"] = <your_ak>
os.environ["QIANFAN_SK"] = <your_sk>
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = <your_api_key>
from langchain_community.llms.baidu_qianfan_endpoint import QianfanLLMEndpoint
model = QianfanLLMEndpoint(streaming=True)
print(model.invoke("简单介绍一下自己"))输出结果
语言模型
1、大语言模型(LLM) ,也叫 Text Model,这些模型将文本字符串作为输入,并返回文本字符串作为输出。Open AI 的 text-davinci-003、Facebook 的 LLaMA、ANTHROPIC 的 Claude,都是典型的 LLM。
2、聊天模型(Chat Model),主要代表 Open AI 的 ChatGPT 系列模型。这些模型通常由语言模型支持,但它们的 API 更加结构化。具体来说,这些模型将聊天消息列表作为输入,并返回聊天消息。
3、文本嵌入模型(Embedding Model),这些模型将文本作为输入并返回浮点数列表,也就是 Embedding。而文本嵌入模型如 OpenAI 的 text-embedding-ada-002。文本嵌入模型负责把文档存入向量数据库。
输入、调用、解析
使用模型的过程可以归纳为三个环节
1、对模型进行输入:可以自己去手写模版,例如最简单的提问,介绍一下你自己,也可以使用角色扮演的形式,存在系统提示词(system),和human输入,ai则负责进行输出
2、调用:对模型进行调用,市面上有各种大模型,各种提供商,对这些底层的调用
3、解析:大模型进行返回后,需要一些解析器对大模型的输出进行解析,格式化,可以将大模型返回的非结构化文本,转换成程序可以处理的结构化文本,例如转换为JSON
简单示例
import os
os.environ["QIANFAN_AK"] = <your_ak>
os.environ["QIANFAN_SK"] = <your_sk>
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = <your_api_key>
from langchain_community.llms import QianfanLLMEndpoint
model = QianfanLLMEndpoint(streaming=True)
# 导入聊天消息类模板
from langchain.prompts import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
# 模板的构建
template="你是一位专业顾问,负责为专注于{product}的公司起名。"
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template="公司主打产品是{product_detail}。"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
prompt_template = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
from langchain.chat_models import QianfanChatEndpoint
# 格式化提示消息生成提示
prompt = prompt_template.format_prompt(product="儿童图书", product_detail="益智阅读").to_messages()
print(prompt)
print("=========================")
chat = QianfanChatEndpoint()
result = chat(prompt)
print(result)输出结果
提示工程
提示工程(Prompt Engineering)
是设计和优化输入文本(提示)以引导大语言模型(如ChatGPT)生成所需输出的过程。通过精心设计的提示,可以提高模型的响应质量和准确性。
大语言模型如ChatGPT能够理解和生成自然语言,但它们的输出质量很大程度上取决于输入的提示。提示工程就是通过实验和调整,找到能够引导模型产生最佳结果的输入方式。
1、提高准确性: 不同的提示可能导致模型生成不同的结果。通过优化提示,可以更准确地获得所需信息。
2、增加灵活性: 提示工程可以帮助模型适应不同的任务和场景,从回答问题到生成创意内容。
3、节省时间: 精心设计的提示可以减少反复尝试的时间,提高工作效率。
通过提示工程,我们可以更有效地利用大语言模型的能力,获取更有价值的输出。
提示的结构
### INSTRUCTIONS
- Answer the question based on the context below. If the question cannot be answered using the information provided answer with "I don't know".
根据以下上下文回答问题。如果无法使用提供的信息回答问题,请回答“我不知道”。
---
#### CONTEXTS (EXTERNAL INFO)
- Context: Large Language Models (LLMs) are the latest models used in NLP. Their superior performance over smaller models has made them incredibly useful for developers building NLP enabled applications. These models can be accessed via Hugging Face's `transformers` library, via OpenAI using the 'openai' library, and via Cohere using the ‘cohere’ library.
Context:大型语言模型(LLMs)是NLP中使用的最新模型。与较小的模型相比,它们的卓越性能使它们对构建NLP应用程序的开发人员非常有用。这些模型可以通过Hugging Face的“transformers”库、OpenAI的“OpenAI”库和Cohere的“cohre”库访问。
---
#### Question:
- Which libraries and model providers offer LLMs?
哪些库和模型提供商提供LLM?
---
#### Answer:
- Answer:
---
### OUTPUT INDICATOR
PROMPTER INPUT在这个提示框架中:
指令(Instuction) 告诉模型这个任务大概要做什么、怎么做,比如如何使用提供的外部信息、如何处理查询以及如何构造输出。这通常是一个提示模板中比较固定的部分。一个常见用例是告诉模型“你是一个有用的 XX 助手”,这会让他更认真地对待自己的角色。
上下文(Context) 则充当模型的额外知识来源。这些信息可以手动插入到提示中,通过矢量数据库检索得来,或通过其他方式(如调用 API、计算器等工具)拉入。一个常见的用例时是把从向量数据库查询到的知识作为上下文传递给模型。
提示输入(Prompt Input) 通常就是具体的问题或者需要大模型做的具体事情,这个部分和“指令”部分其实也可以合二为一。但是拆分出来成为一个独立的组件,就更加结构化,便于复用模板。这通常是作为变量,在调用模型之前传递给提示模板,以形成具体的提示。
输出指示器(Output Indicator) 标记要生成的文本的开始。这就像我们小时候的数学考卷,先写一个“解”,就代表你要开始答题了。如果生成 Python 代码,可以使用 “import” 向模型表明它必须开始编写 Python 代码(因为大多数 Python 脚本以 import 开头)。这部分在我们和 ChatGPT 对话时往往是可有可无的,当然 LangChain 中的代理在构建提示模板时,经常性的会用一个“Thought:”(思考)作为引导词,指示模型开始输出自己的推理(Reasoning)。
LangChain提示模版
LangChain 中提供 String(StringPromptTemplate)和 Chat(BaseChatPromptTemplate)两种基本类型的模板,并基于它们构建了不同类型的提示模板:
| 提示模版 | 含义 |
|---|---|
| PromptTemplate | 这是最常用的 String 提示模板 |
| ChatPromptTemplate | 常用的 Chat 提示模板,用于组合各种角色的消息模板,传入聊天模型 (Chat Model),具体消息模板包括 ChatMessagePromptTemplate、HumanMessagePromptTemplate、AIMessagePromptTemplate 和 SystemMessagePromptTemplate。 |
| FewShotPromptTemplate | 少样本本提示模板,通过示例的展示来“教”模型如何回答 |
| PipelinePrompt | 用于把几个提示组合在一起使用 |
| 自定义模 | LangChain 还允许你基于其他模板类来定制自己的提示模版 |
PromptTemplate
示例一:
from langchain_core.prompts import PromptTemplate
template = """你是业务咨询顾问。你给一个销售{product}的电商公司,起一个好的名字?"""
prompt = PromptTemplate.from_template(template)
print(prompt.format(product="儿童图书"))输出结果
你是业务咨询顾问。你给一个销售儿童图书的电商公司,起一个好的名字?
在这里,"你是业务咨询顾问。你给一个销售{product}的电商公司,起一个好的名字?" 就是原始提示模板,其中 {product} 是占位符。
示例二:
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate(
input_variables=["product", "market"],
template="你是业务咨询顾问。对于一个面向{market}市场的,专注于销售{product}的公司,你会推荐哪个名字?"
)
print(prompt.format(product="儿童图书", market="大众"))输出结果
你是业务咨询顾问。对于一个面向大众市场的,专注于销售儿童图书的公司,你会推荐哪个名字?
ChatPromptTemplate
与PromptTemplate不同之处就是,它们有对应的角色
示例:
import os
os.environ["QIANFAN_AK"] = <your_ak>
os.environ["QIANFAN_SK"] = <your_sk>
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = <your_api_key>
from langchain_core.prompts import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain_community.chat_models.baidu_qianfan_endpoint import QianfanChatEndpoint
template = "你是一位专业的顾问,负责为专注于{product}的公司起名。"
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template = "公司主打产品是{product_detail}。"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
prompt_template = ChatPromptTemplate.from_messages([
system_message_prompt,
human_message_prompt
])
prompt = prompt_template.format_prompt(product="图书销售", product_detail="儿童图书").to_messages()
chat = QianfanChatEndpoint()
result = chat(prompt)
print(result)输出
content='好的,根据您的要求,我为专注于儿童图书销售的公司起名:\n\n1. **童阅书坊**:这个名字体现了儿童的阅读活动,“童阅”突出了主要客户群体——儿童,而“书坊”则暗示了图书的多样性和丰富的选择。\n2. **乐学童书阁**:这个名字突出了教育性质,“乐学”表达了一种愉悦的学习态度,与“童书阁”结合,形成了一个充满知识的儿童天地。\n3. **宝宝乐园书店**:“宝宝”直接指向了儿童客户群,“乐园”则传达了快乐和探索的意味,整体上这个名称轻松愉悦。\n4. **知识宝库童书馆**:结合了知识的传递和儿童的快乐学习,给人一种富有知识性又有趣的感觉。\n5. **启蒙园地**:此名简单易记,表达了教育启蒙和孩子成长的重要性。\n\n这些名称都是基于您公司主打产品是儿童图书这一核心特点来设计的,旨在体现公司的业务范围和目标客户群体。请注意,这些建议仅供参考,您需要确保所选名称在商业注册和商标方面没有重复或冲突。' additional_kwargs={'finish_reason': '', 'request_id': 'as-8umhgtqdtk', 'object': 'chat.completion', 'search_info': []} response_metadata={'token_usage': {'prompt_tokens': 22, 'completion_tokens': 238, 'total_tokens': 260}, 'model_name': None, 'finish_reason': 'stop', 'id': 'as-8umhgtqdtk', 'object': 'chat.completion', 'created': 1727238674, 'result': '好的,根据您的要求,我为专注于儿童图书销售的公司起名:\n\n1. **童阅书坊**:这个名字体现了儿童的阅读活动,“童阅”突出了主要客户群体——儿童,而“书坊”则暗示了图书的多样性和丰富的选择。\n2. **乐学童书阁**:这个名字突出了教育性质,“乐学”表达了一种愉悦的学习态度,与“童书阁”结合,形成了一个充满知识的儿童天地。\n3. **宝宝乐园书店**:“宝宝”直接指向了儿童客户群,“乐园”则传达了快乐和探索的意味,整体上这个名称轻松愉悦。\n4. **知识宝库童书馆**:结合了知识的传递和儿童的快乐学习,给人一种富有知识性又有趣的感觉。\n5. **启蒙园地**:此名简单易记,表达了教育启蒙和孩子成长的重要性。\n\n这些名称都是基于您公司主打产品是儿童图书这一核心特点来设计的,旨在体现公司的业务范围和目标客户群体。请注意,这些建议仅供参考,您需要确保所选名称在商业注册和商标方面没有重复或冲突。', 'is_truncated': False, 'need_clear_history': False, 'usage': {'prompt_tokens': 22, 'completion_tokens': 238, 'total_tokens': 260}} id='run-b60017b4-1c37-4a0e-abc9-f400671b55b1-0' usage_metadata={'input_tokens': 22, 'output_tokens': 238, 'total_tokens': 260}
FewShotPromptTemplate
FewShot 的思想起源
举个例子
今天我下楼跑步时,一个老爷爷教孙子学骑车,小孩总掌握不了平衡,蹬一两下就下车。
爷爷说:“宝贝,你得有毅力!”
孙子说:“爷爷,什么是毅力?”
爷爷说:“你看这个叔叔,绕着楼跑了 10 多圈了,这就是毅力,你也得至少蹬个 10 几趟才能骑起来。”
这老爷爷就是给孙子做了一个 One-Shot 学习。如果他的孙子第一次听说却上来就明白什么是毅力,那就神了,这就叫 Zero-Shot,表明这孩子的语言天赋不是一般的高,从知识积累和当前语境中就能够推知新词的涵义。有时候我们把 Zero-Shot 翻译为“顿悟”,聪明的大模型,某些情况下也是能够做到的。
Few-Shot(少样本)、One-Shot(单样本)和与之对应的 Zero-Shot(零样本)的概念都起源于机器学习。如何让机器学习模型在极少量甚至没有示例的情况下学习到新的概念或类别,对于许多现实世界的问题是非常有价值的,因为我们往往无法获取到大量的标签化数据。
在提示工程(Prompt Engineering)中,Few-Shot 和 Zero-Shot 学习的概念也被广泛应用。
- 在 Few-Shot 学习设置中,模型会被给予几个示例,以帮助模型理解任务,并生成正确的响应。
- 在 Zero-Shot 学习设置中,模型只根据任务的描述生成响应,不需要任何示例。
示例:
"""For basic init and call"""
import os
os.environ["QIANFAN_AK"] = <your_ak>
os.environ["QIANFAN_SK"] = <your_sk>
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = <your_api_key>
from langchain_community.llms import QianfanLLMEndpoint
model = QianfanLLMEndpoint(streaming=True)
# 1. 创建一些示例
samples = [
{
"flower_type": "玫瑰",
"occasion": "爱情",
"ad_copy": "玫瑰,浪漫的象征,是你向心爱的人表达爱意的最佳选择。"
},
{
"flower_type": "康乃馨",
"occasion": "母亲节",
"ad_copy": "康乃馨代表着母爱的纯洁与伟大,是母亲节赠送给母亲的完美礼物。"
},
{
"flower_type": "百合",
"occasion": "庆祝",
"ad_copy": "百合象征着纯洁与高雅,是你庆祝特殊时刻的理想选择。"
},
{
"flower_type": "向日葵",
"occasion": "鼓励",
"ad_copy": "向日葵象征着坚韧和乐观,是你鼓励亲朋好友的最好方式。"
}
]
# 2. 创建一个提示模板
from langchain_core.prompts import PromptTemplate
template="鲜花类型: {flower_type}\n场合: {occasion}\n文案: {ad_copy}"
prompt_sample = PromptTemplate(input_variables=["flower_type", "occasion", "ad_copy"],
template=template)
# print(prompt_sample.format(**samples[0]))
# 3. 创建一个FewShotPromptTemplate对象
from langchain_core.prompts import FewShotPromptTemplate
prompt = FewShotPromptTemplate(
examples=samples,
example_prompt=prompt_sample,
suffix="鲜花类型: {flower_type}\n场合: {occasion}",
input_variables=["flower_type", "occasion"]
)
print(prompt.format(flower_type="野玫瑰", occasion="爱情"))
print("=======================================")
res = model(prompt.format(flower_type="野玫瑰", occasion="爱情"))
print(res)输出
鲜花类型: 玫瑰
场合: 爱情
文案: 玫瑰,浪漫的象征,是你向心爱的人表达爱意的最佳选择。
鲜花类型: 康乃馨
场合: 母亲节
文案: 康乃馨代表着母爱的纯洁与伟大,是母亲节赠送给母亲的完美礼物。
鲜花类型: 百合
场合: 庆祝
文案: 百合象征着纯洁与高雅,是你庆祝特殊时刻的理想选择。
鲜花类型: 向日葵
场合: 鼓励
文案: 向日葵象征着坚韧和乐观,是你鼓励亲朋好友的最好方式。
鲜花类型: 野玫瑰
场合: 爱情
文案: 野玫瑰,深邃的象征,是在独特而又炽热的情感中表达对爱情的无限忠诚与坚守。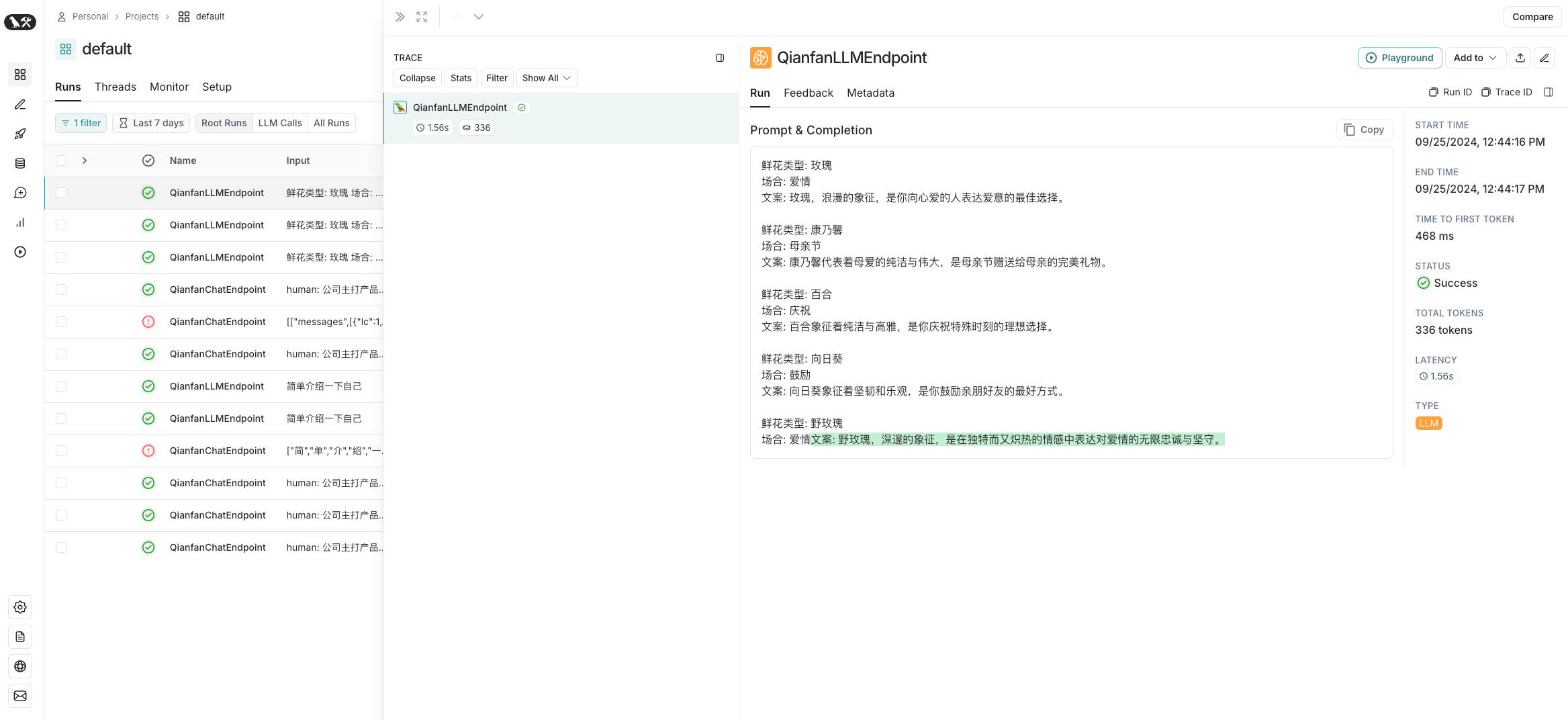
思维链与思维树
Chain Of Thought
什么是Chain Of Thought?
CoT 这个概念来源于学术界,是谷歌大脑的 Jason Wei 等人于 2022 年在论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models(自我一致性提升了语言模型中的思维链推理能力)》中提出来的概念。它提出,如果生成一系列的中间推理步骤,就能够显著提高大型语言模型进行复杂推理的能力。
Few-Shot CoT
Few-Shot CoT 简单的在提示中提供了一些链式思考示例(Chain-of-Thought Prompting),足够大的语言模型的推理能力就能够被增强。简单说,就是给出一两个示例,然后在示例中写清楚推导的过程。 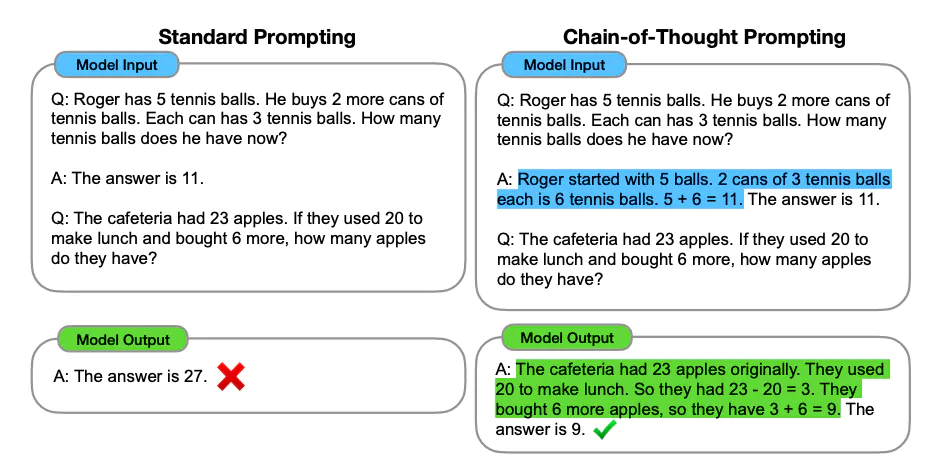
给出了一个大模型通过思维链做数学题的示例。图左和图右,大模型都读入了 OneShot 示例,但是图左只给出了答案,而图右则在 OneShot 示例中给出了解题的具体思路。结果,只给出了答案的模型推理错误,而给出解题思路后,同一个模型生成了正确的答案。
Zero-Shot CoT
在 Zero-Shot CoT 中,你只要简单地告诉模型“让我们一步步的思考(Let’s think step by step)”,模型就能够给出更好的答案! 
Few-Shot CoT,指的就是在带有示例的提示过程中,加入思考的步骤,从而引导模型给出更好的结果。而 Zero-Shot CoT,就是直接告诉模型要一步一步地思考,慢慢地推理。
COT示例:
# 设置环境变量和API密钥
import os
os.environ["QIANFAN_AK"] = <your_ak>
os.environ["QIANFAN_SK"] = <your_sk>
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = <your_api_key>
# 创建聊天模型
from langchain_community.chat_models.baidu_qianfan_endpoint import QianfanChatEndpoint
llm = QianfanChatEndpoint(temperature=0.1)
# 设定 AI 的角色和目标
role_template = "你是一个为花店电商公司工作的AI助手, 你的目标是帮助客户根据他们的喜好做出明智的决定"
cot_template = """
作为一个为花店电商公司工作的AI助手,我的目标是帮助客户根据他们的喜好做出明智的决定。
我会按部就班的思考,先理解客户的需求,然后考虑各种鲜花的涵义,最后根据这个需求,给出我的推荐。
同时,我也会向客户解释我这样推荐的原因。
示例 1:
人类:我想找一种象征爱情的花。
AI:首先,我理解你正在寻找一种可以象征爱情的花。在许多文化中,红玫瑰被视为爱情的象征,这是因为它们的红色通常与热情和浓烈的感情联系在一起。因此,考虑到这一点,我会推荐红玫瑰。红玫瑰不仅能够象征爱情,同时也可以传达出强烈的感情,这是你在寻找的。
示例 2:
人类:我想要一些独特和奇特的花。
AI:从你的需求中,我理解你想要的是独一无二和引人注目的花朵。兰花是一种非常独特并且颜色鲜艳的花,它们在世界上的许多地方都被视为奢侈品和美的象征。因此,我建议你考虑兰花。选择兰花可以满足你对独特和奇特的要求,而且,兰花的美丽和它们所代表的力量和奢侈也可能会吸引你。
"""
from langchain_core.prompts import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate
)
system_prompt_role = SystemMessagePromptTemplate.from_template(role_template)
system_prompt_cot = SystemMessagePromptTemplate.from_template(cot_template)
# 用户的询问
human_template = "{human_input}"
human_prompt = HumanMessagePromptTemplate.from_template(human_template)
# 将以上所有信息结合为一个聊天提示
chat_prompt = ChatPromptTemplate.from_messages([system_prompt_role, system_prompt_cot, human_prompt])
prompt = chat_prompt.format_prompt(human_input="我想为我的女朋友购买一些花。她喜欢粉色和紫色。你有什么建议吗?").to_messages()
print(prompt)
print("========================================")
# 接收用户的询问,返回回答结果
response = llm(prompt)
print(response.content)输出
首先,我理解你希望为你的女朋友购买一些她喜欢的花。她喜欢粉色和紫色,这为我们选择提供了很好的方向。粉色和紫色的花朵通常与温柔、浪漫和优雅的情感联系在一起。
考虑到这些特点,我推荐你选择粉色康乃馨和紫色玫瑰的组合。这两种花都是非常受欢迎的,并且具有浪漫的寓意。粉色康乃馨通常代表爱和关怀,而紫色玫瑰则象征着浪漫和尊贵。
此外,你还可以考虑添加一些粉色或紫色的满天星或紫罗兰作为装饰,以增加整体的视觉效果。这样的组合不仅符合你女朋友对颜色的喜好,同时也能够传达出你对她的爱和关怀。
当然,如果你希望更加个性化,你可以根据你和你女朋友的特殊回忆或她喜欢的花卉种类进行选择。希望这些建议能够帮助你做出明智的决定。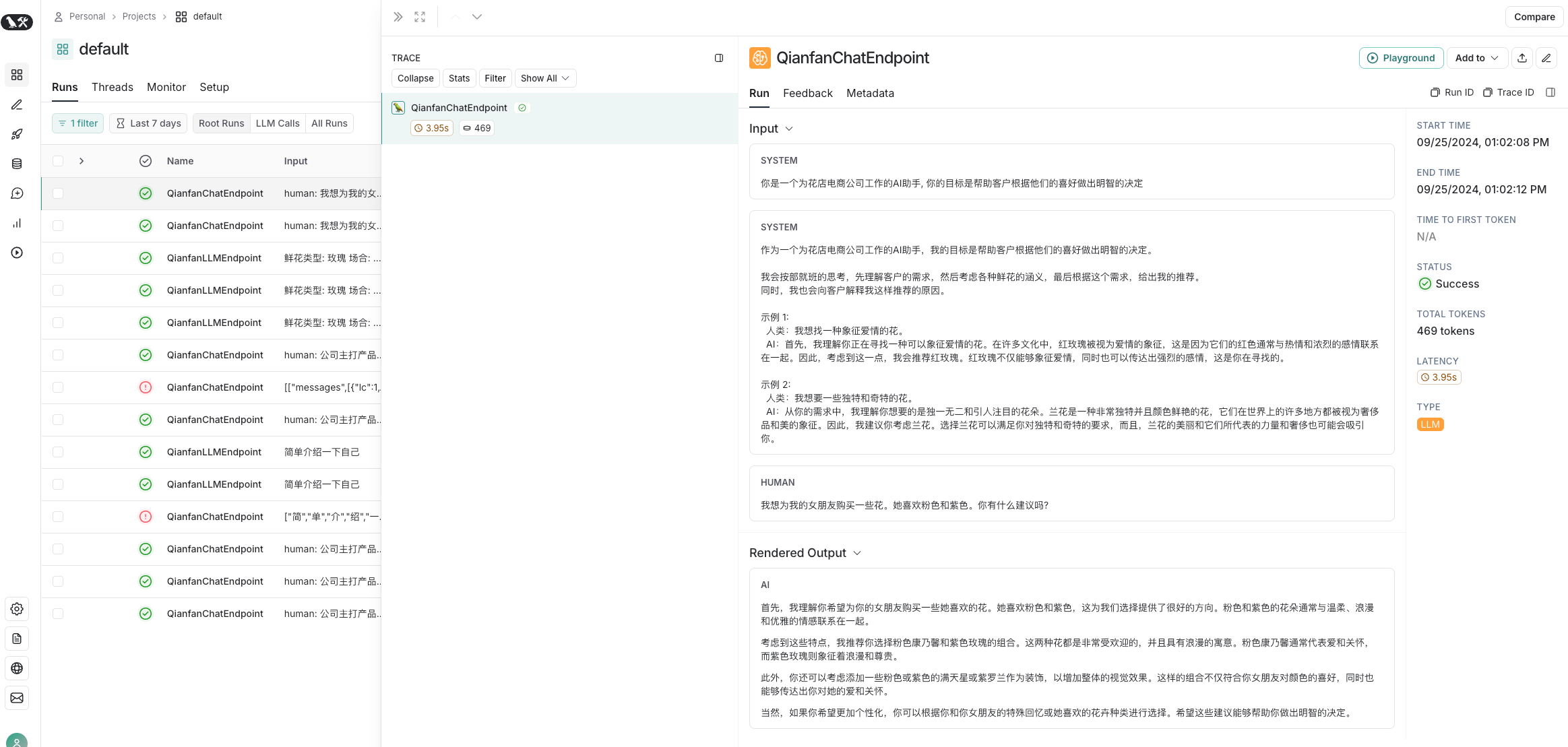
Tree of Thought
CoT 这种思想,为大模型带来了更好的答案,然而,对于需要探索或预判战略的复杂任务来说,传统或简单的提示技巧是不够的。基于 CoT 的思想,Yao 和 Long 等人几乎在同一时间在论文《思维之树:使用大型语言模型进行深思熟虑的问题解决》和《大型语言模型指导的思维之树》中,进一步提出了思维树(Tree of Thoughts,ToT)框架,该框架基于思维链提示进行了总结,引导语言模型探索把思维作为中间步骤来解决通用问题。
ToT 是一种解决复杂问题的框架,它在需要多步骤推理的任务中,引导语言模型搜索一棵由连贯的语言序列(解决问题的中间步骤)组成的思维树,而不是简单地生成一个答案。ToT 框架的核心思想是:让模型生成和评估其思维的能力,并将其与搜索算法(如广度优先搜索和深度优先搜索)结合起来,进行系统性地探索和验证。
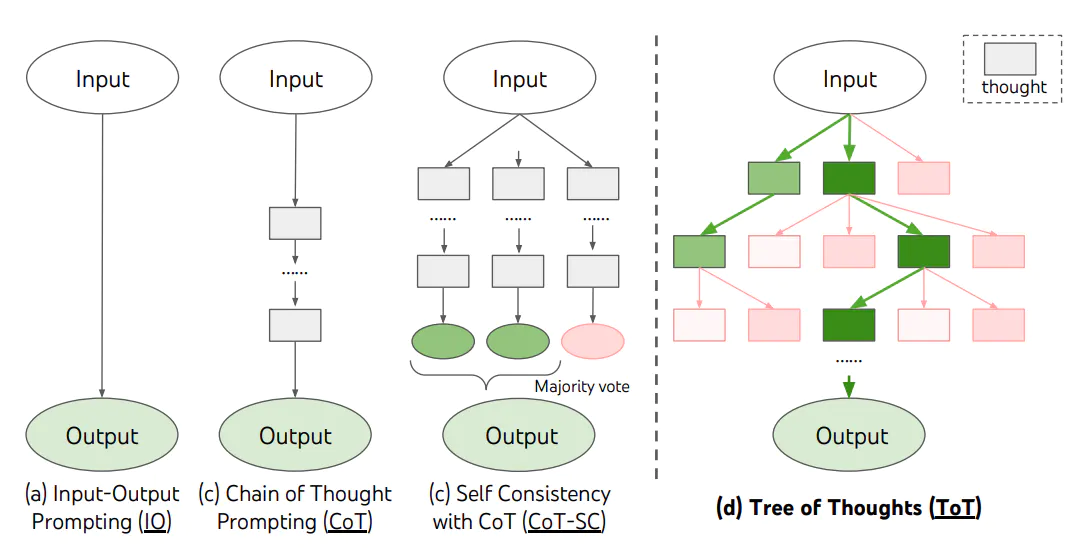 ToT 框架为每个任务定义具体的思维步骤和每个步骤的候选项数量。例如,要解决一个数学推理任务,先把它分解为 3 个思维步骤,并为每个步骤提出多个方案,并保留最优的 5 个候选方案。然后在多条思维路径中搜寻最优的解决方案。
ToT 框架为每个任务定义具体的思维步骤和每个步骤的候选项数量。例如,要解决一个数学推理任务,先把它分解为 3 个思维步骤,并为每个步骤提出多个方案,并保留最优的 5 个候选方案。然后在多条思维路径中搜寻最优的解决方案。
这种方法的优势在于,模型可以通过观察和评估其自身的思维过程,更好地解决问题,而不仅仅是基于输入生成输出。这对于需要深度推理的复杂任务非常有用。此外,通过引入强化学习、集束搜索等技术,可以进一步提高搜索策略的性能,并让模型在解决新问题或面临未知情况时有更好的表现。
TOT示例:
# 设置环境变量和API密钥
import os
os.environ["QIANFAN_AK"] = <your_ak>
os.environ["QIANFAN_SK"] = <your_sk>
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = <your_api_key>
# 创建聊天模型
from langchain_community.chat_models.baidu_qianfan_endpoint import QianfanChatEndpoint
llm = QianfanChatEndpoint(temperature=0.1)
# 设定 AI 的角色和目标
role_template = "你是一个为花店电商公司工作的AI助手, 你的目标是帮助客户根据他们的喜好做出明智的决定"
cot_template = """
作为一个为花店电商公司工作的AI助手,我的目标是帮助客户根据他们的喜好做出明智的决定。
我会按部就班的思考,先理解客户的需求,然后考虑各种鲜花的涵义,最后根据这个需求,给出我的推荐。
同时,我也会向客户解释我这样推荐的原因。
思维步骤 1:理解顾客的需求。
顾客想为妻子购买鲜花。
顾客的妻子喜欢淡雅的颜色和花香。
思维步骤 2:考虑可能的鲜花选择。
候选 1:百合,因为它有淡雅的颜色和花香。
候选 2:玫瑰,选择淡粉色或白色,它们通常有花香。
候选 3:紫罗兰,它有淡雅的颜色和花香。
候选 4:桔梗,它的颜色淡雅但不一定有花香。
候选 5:康乃馨,选择淡色系列,它们有淡雅的花香。
思维步骤 3:根据顾客的需求筛选最佳选择。
百合和紫罗兰都符合顾客的需求,因为它们都有淡雅的颜色和花香。
淡粉色或白色的玫瑰也是一个不错的选择。桔梗可能不是最佳选择,因为它可能没有花香。
康乃馨是一个可考虑的选择。
思维步骤 4:给出建议。
“考虑到您妻子喜欢淡雅的颜色和花香,我建议您可以选择百合或紫罗兰。淡粉色或白色的玫瑰也是一个很好的选择。希望这些建议能帮助您做出决策!”
"""
from langchain_core.prompts import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate
)
system_prompt_role = SystemMessagePromptTemplate.from_template(role_template)
system_prompt_cot = SystemMessagePromptTemplate.from_template(cot_template)
# 用户的询问
human_template = "{human_input}"
human_prompt = HumanMessagePromptTemplate.from_template(human_template)
# 将以上所有信息结合为一个聊天提示
chat_prompt = ChatPromptTemplate.from_messages([system_prompt_role, system_prompt_cot, human_prompt])
prompt = chat_prompt.format_prompt(human_input="我想为我的女朋友购买一些花。她喜欢粉色和紫色。你有什么建议吗?").to_messages()
print(prompt)
print("========================================")
# 接收用户的询问,返回回答结果
response = llm(prompt)
print(response.content)输出
考虑到您的女朋友喜欢粉色和紫色,我建议您可以选择粉色康乃馨和紫色紫罗兰的组合。这两种花都有独特的颜色,并且通常被视为表达爱意和浪漫的象征。此外,它们也有着淡雅的花香,相信会让她感到愉悦和特别。如果您想更进一步地表达您的情感,您还可以选择带有小卡片的花束,写上您的祝福和心意。希望这些建议能帮到您!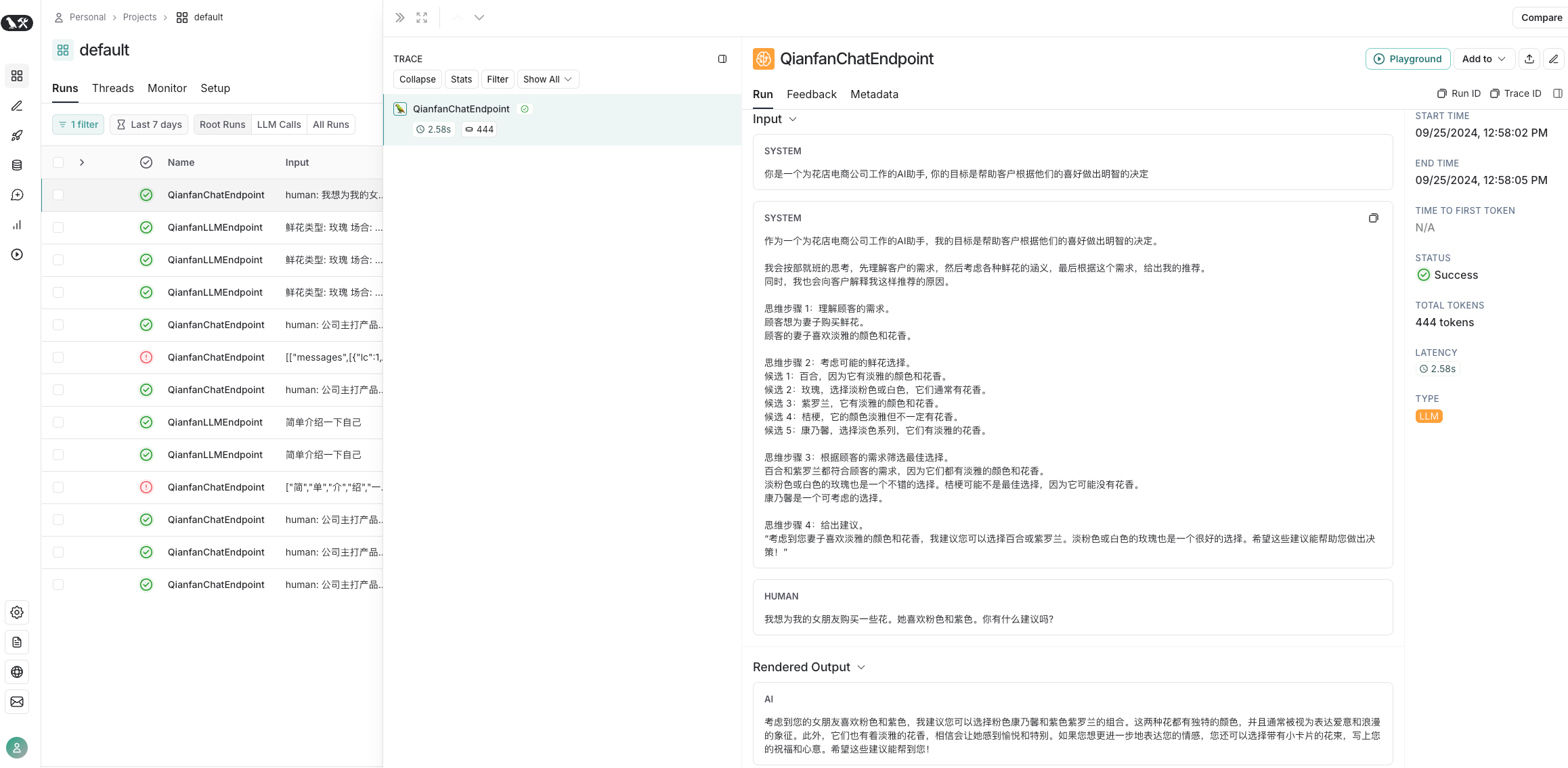
输出格式化
语言模型输出的是文本,这是给人类阅读的。但很多时候,你可能想要获得的是程序能够处理的结构化信息。这就是输出解析器发挥作用的地方。
输出解析器是一种专用于处理和构建语言模型响应的类。一个基本的输出解析器类通常需要实现两个核心方法。
LangChain支持的解析器:
1、列表解析器(List Parser): 这个解析器用于处理模型生成的输出,当需要模型的输出是一个列表的时候使用。例如,如果你询问模型“列出所有鲜花的库存”,模型的回答应该是一个列表。
2、日期时间解析器(Datetime Parser): 这个解析器用于处理日期和时间相关的输出,确保模型的输出是正确的日期或时间格式。
3、枚举解析器(Enum Parser): 这个解析器用于处理预定义的一组值,当模型的输出应该是这组预定义值之一时使用。例如,如果你定义了一个问题的答案只能是“是”或“否”,那么枚举解析器可以确保模型的回答是这两个选项之一。
4、结构化输出解析器(Structured Output Parser): 这个解析器用于处理复杂的、结构化的输出。如果你的应用需要模型生成具有特定结构的复杂回答(例如一份报告、一篇文章等),那么可以使用结构化输出解析器来实现。
5、Pydantic(JSON)解析器: 这个解析器用于处理模型的输出,当模型的输出应该是一个符合特定格式的 JSON 对象时使用。它使用 Pydantic 库,这是一个数据验证库,可以用于构建复杂的数据模型,并确保模型的输出符合预期的数据模型。
6、自动修复解析器(Auto-Fixing Parser): 这个解析器可以自动修复某些常见的模型输出错误。例如,如果模型的输出应该是一段文本,但是模型返回了一段包含语法或拼写错误的文本,自动修复解析器可以自动纠正这些错误。
7、重试解析器(RetryWithErrorOutputParser): 这个解析器用于在模型的初次输出不符合预期时,尝试修复或重新生成新的输出。例如,如果模型的输出应该是一个日期,但是模型返回了一个字符串,那么重试解析器可以重新提示模型生成正确的日期格式。
Pydantic(JSON)解析器
Pydantic 是一个 Python 数据验证和设置管理库,主要基于 Python 类型提示。虽然它不是专为 JSON 设计的,但由于 JSON 是现代 Web 应用和 API 交互中的常见数据格式,Pydantic 负责处理和验证 JSON 数据。
示例:
# 设置环境变量和API密钥
import os
os.environ["QIANFAN_AK"] = <your_ak>
os.environ["QIANFAN_SK"] = <your_sk>
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = <your_api_key>
from langchain_community.llms import QianfanLLMEndpoint
llm = QianfanLLMEndpoint()
# ------Part 2
# 创建一个空的DataFrame用于存储结果
import pandas as pd
df = pd.DataFrame(columns=["flower_type", "price", "description", "reason"])
# 数据准备
flowers = ["玫瑰", "百合", "康乃馨"]
prices = ["50", "30", "20"]
# 定义我们想要接收的数据格式
from pydantic import BaseModel, Field
class FlowerDescription(BaseModel):
flower_type: str = Field(description="鲜花的种类")
price: int = Field(description="鲜花的价格")
description: str = Field(description="鲜花的描述文案")
reason: str = Field(description="为什么要这样写这个文案")
# ------Part 3
# 创建输出解析器
from langchain.output_parsers import PydanticOutputParser
output_parser = PydanticOutputParser(pydantic_object=FlowerDescription)
# 获取输出格式指示
format_instructions = output_parser.get_format_instructions()
# 打印提示
print("输出格式:",format_instructions)
print("============================================")
# ------Part 4
# 创建提示模板
from langchain.prompts import PromptTemplate
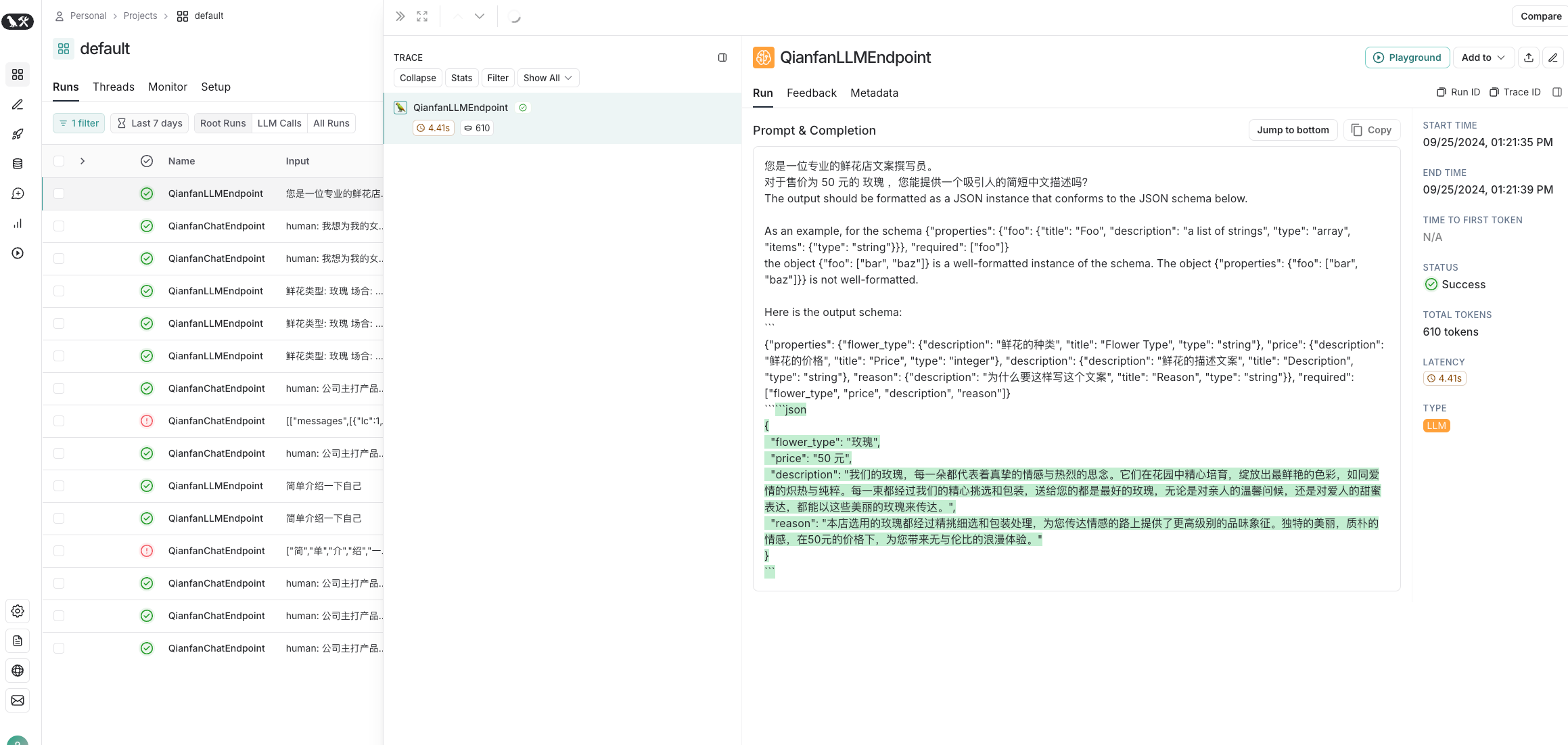
prompt_template = """您是一位专业的鲜花店文案撰写员。
对于售价为 {price} 元的 {flower} ,您能提供一个吸引人的简短中文描述吗?
{format_instructions}"""
# 根据模板创建提示,同时在提示中加入输出解析器的说明
prompt = PromptTemplate.from_template(prompt_template,
partial_variables={"format_instructions": format_instructions})
# 打印提示
# print("提示:", prompt)
print("============================================")
# ------Part 5
for flower, price in zip(flowers, prices):
# 根据提示准备模型的输入
input = prompt.format(flower=flower, price=price)
# 打印提示
print("提示:", input)
# 获取模型的输出
output = llm(input)
# 解析模型的输出
parsed_output = output_parser.parse(output)
parsed_output_dict = parsed_output.dict() # 将Pydantic格式转换为字典
# 将解析后的输出添加到DataFrame中
df.loc[len(df)] = parsed_output.dict()
# 打印字典
print("输出的数据:", df.to_dict(orient='records'))输出
自动修复解析器(OutputFixingParser)
示例:
# 设置环境变量和API密钥
import os
os.environ["QIANFAN_AK"] = <your_ak>
os.environ["QIANFAN_SK"] = <your_sk>
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = <your_api_key>
from langchain_community.llms.baidu_qianfan_endpoint import QianfanLLMEndpoint
llm = QianfanLLMEndpoint()
# 导入所需要的库和模块
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
from typing import List
# 使用Pydantic创建一个数据格式,表示花
class Flower(BaseModel):
name: str = Field(description="name of a flower")
colors: List[str] = Field(description="the colors of this flower")
# 定义一个用于获取某种花的颜色列表的查询
flower_query = "Generate the charaters for a random flower."
# 定义一个格式不正确的输出
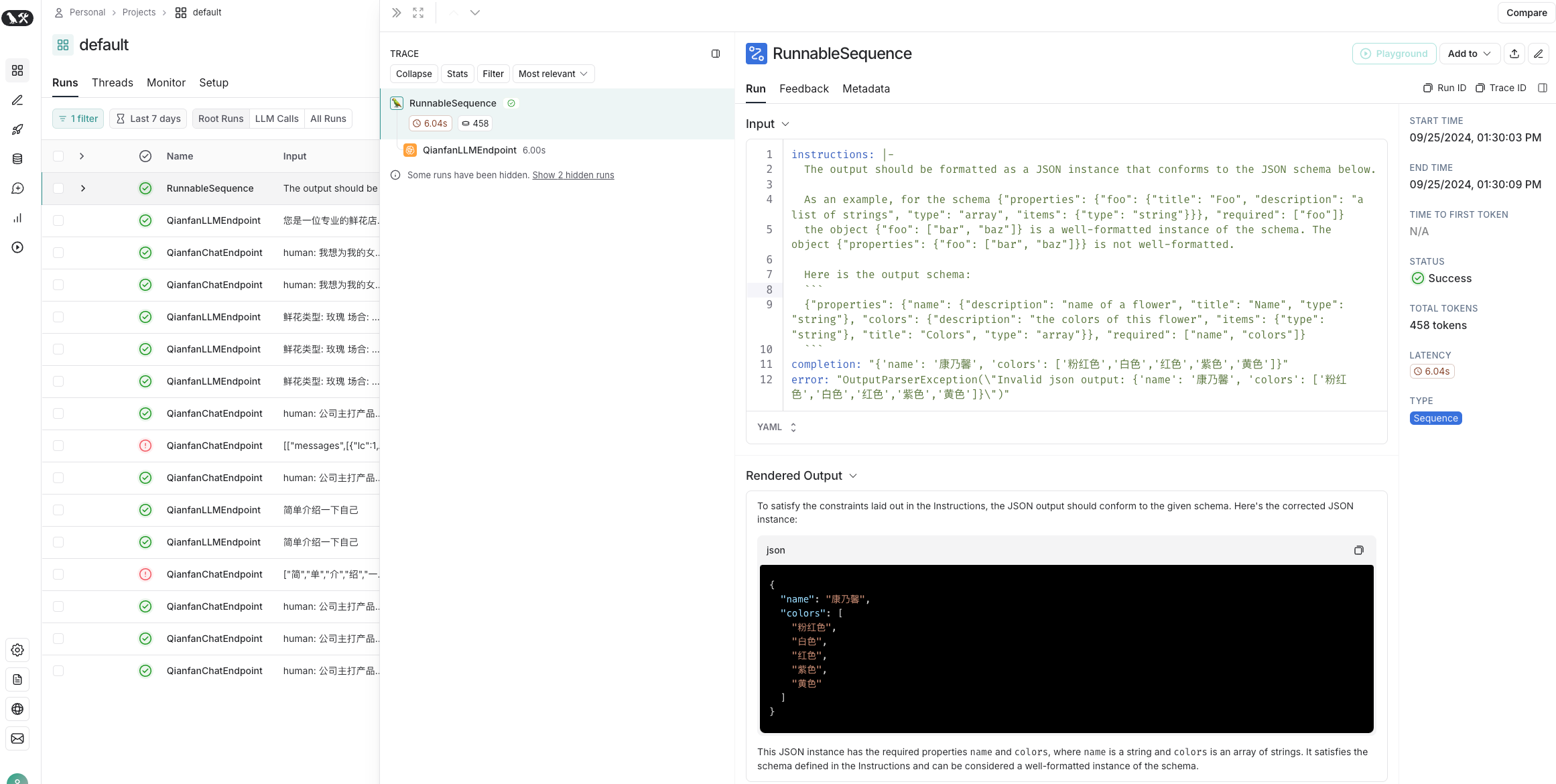
misformatted = "{'name': '康乃馨', 'colors': ['粉红色','白色','红色','紫色','黄色']}"
# 创建一个用于解析输出的Pydantic解析器,此处希望解析为Flower格式
parser = PydanticOutputParser(pydantic_object=Flower)
# # 使用Pydantic解析器解析不正确的输出
# parser.parse(misformatted)
# 从langchain库导入所需的模块
from langchain.output_parsers import OutputFixingParser
# 使用OutputFixingParser创建一个新的解析器,该解析器能够纠正格式不正确的输出
new_parser = OutputFixingParser.from_llm(parser=parser, llm=llm)
# 使用新的解析器解析不正确的输出
result = new_parser.parse(misformatted) # 错误被自动修正
print(result) # 打印解析后的输出结果输出
重试解析器(RetryWithErrorOutputParser)
OutputFixingParser 不错,但它只能做简单的格式修复。如果出错的不只是格式,比如,输出根本不完整,有缺失内容,那么仅仅根据输出和格式本身,是无法修复它的。
# 设置环境变量和API密钥
import os
os.environ["QIANFAN_AK"] = <your_ak>
os.environ["QIANFAN_SK"] = <your_sk>
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = <your_api_key>
from langchain_community.llms.baidu_qianfan_endpoint import QianfanLLMEndpoint
llm = QianfanLLMEndpoint()
# 定义一个模板字符串,这个模板将用于生成提问
# template = """Based on the user question, provide an Action and Action Input for what step should be taken.
# {format_instructions}
# Question: {query}
# Response:"""
# 定义一个Pydantic数据格式,它描述了一个"行动"类及其属性
from pydantic import BaseModel, Field
class Action(BaseModel):
action: str = Field(description="action to take")
action_input: str = Field(description="input to the action")
# 使用Pydantic格式Action来初始化一个输出解析器
from langchain.output_parsers import PydanticOutputParser
parser = PydanticOutputParser(pydantic_object=Action)
# 定义一个提示模板,它将用于向模型提问
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
prompt_value = prompt.format_prompt(query="What are the colors of Orchid?")
# 定义一个错误格式的字符串
bad_response = '{"action": "search"}'
# parser.parse(bad_response) # 如果直接解析,它会引发一个错误
# from langchain.output_parsers import OutputFixingParser
# fix_parser = OutputFixingParser.from_llm(parser=parser, llm=llm)
# parse_result = fix_parser.parse(bad_response)
# print('OutputFixingParser的parse结果:',parse_result)
print("=============================")
# 初始化RetryWithErrorOutputParser,它会尝试再次提问来得到一个正确的输出
from langchain.output_parsers import RetryWithErrorOutputParser
retry_parser = RetryWithErrorOutputParser.from_llm(
parser=parser, llm=llm
)
parse_result = retry_parser.parse_with_prompt(bad_response, prompt_value)
print('RetryWithErrorOutputParser的parse结果:',parse_result)输出